Vous voyez bien les mots à l’écran, mais le curseur refuse de les surligner. Voici pourquoi cela arrive sous Windows et comment extraire le texte dont vous avez vraiment besoin.
Le problème du PDF « non sélectionnable »
Les mots sont là, sur la page, mais votre curseur ne les surligne pas. Vous glissez la souris sur une phrase et, soit rien ne se passe, soit toute la page se sélectionne d’un bloc, comme une image plate. Dans la plupart des cas, le problème ne vient pas du tout de Windows. Il vient de la façon dont le PDF a été créé.
Un PDF n’est pas automatiquement un vrai document texte. Certains PDF contiennent une véritable couche de texte que vous pouvez sélectionner, rechercher et copier. D’autres ne sont que des images enveloppées dans un conteneur PDF. Et d’autres encore contiennent du texte normal, mais leur créateur a ajouté des restrictions de copie qui empêchent votre lecteur de vous laisser le récupérer.
Cette distinction compte, car copier du texte et extraire du texte avec l’OCR ne sont pas le même travail.
Réponse rapide : si le texte d’un PDF est réel et sélectionnable, des lecteurs intégrés comme Edge, Chrome ou Adobe Reader suffisent généralement. Si la page se comporte comme une seule image, l’OCR est nécessaire. Si le texte semble normal mais refuse quand même de se copier, le fichier comporte peut-être des restrictions de copie. Pour extraire rapidement uniquement le texte visible, le plus pratique est d’essayer d’abord la sélection intégrée. La voie la plus directe consiste à utiliser un outil OCR visuel comme Screenie OCR Tool, qui capture le texte directement à partir de ce que vous voyez déjà à l’écran.
📊 Comparatif : les meilleures façons d’extraire le texte
| Méthode | PDF à vrai texte ? | PDF scannés ? | Idéal pour | Principal compromis |
|---|---|---|---|---|
| Edge / Chrome / Adobe Reader | ✅ Oui | ❌ Non | Copier vite depuis un vrai PDF textuel | Échoue sans couche de texte ou si la copie est restreinte |
| OCR / convertisseurs PDF en ligne | ✅ Oui | ✅ Oui | Conversion d’un document entier | Étape d’envoi, friction supplémentaire, souvent trop lourd pour un paragraphe |
| Éditeurs OCR complets ou suites PDF | ✅ Oui | ✅ Oui | Édition lourde ou traitement de document entier | Plus de configuration et de complexité que nécessaire pour beaucoup |
| Screenie (OCR visuel) | ✅ Oui | ✅ Oui | Récupérer rapidement le texte visible à l’écran | Parfait pour une zone précise, pas pour reconstruire tout un PDF |
La version honnête est simple. Les lecteurs intégrés méritent le crédit : ils sont la meilleure option quand le fichier contient déjà du vrai texte. Les outils OCR en ligne sont pratiques quand vous devez réellement traiter un document entier. Les éditeurs OCR complets peuvent être puissants pour de gros traitements. Mais quand votre véritable situation est « j’ai juste besoin de ce bloc de texte visible, maintenant », un outil OCR visuel est souvent le juste milieu le plus malin.
Ce qui vous empêche vraiment de copier le texte
Si vous ne parvenez pas à copier le texte d’un PDF sous Windows, c’est généralement à cause de l’une de ces trois raisons.
1. Le PDF est en réalité un scan
Un PDF scanné n’est souvent qu’une image à l’intérieur d’un fichier PDF. La page peut paraître parfaitement lisible, mais votre ordinateur ne voit pas des mots. Il voit des pixels.
C’est pour cela que glisser le curseur sélectionne parfois toute la page d’un bloc au lieu d’un mot à la fois. C’est l’un des signes les plus clairs que le fichier ne possède aucune vraie couche de texte.
Qu’est-ce qu’un PDF scanné ? Un PDF scanné est un document où chaque page est stockée comme une image plutôt que comme du texte sélectionnable. Il peut ressembler à un PDF normal, mais la copie échoue parce qu’il n’y a aucun caractère réel sous l’image de la page.
2. Le PDF comporte des restrictions de copie
Un fichier PDF peut inclure des permissions qui limitent ce que le lecteur vous autorise à faire. Une restriction fréquente consiste à désactiver la copie du texte.
Dans ce cas, le texte peut être réel et lisible, mais le logiciel respecte les règles du fichier et refuse de le copier.
Pourquoi un PDF s’ouvre-t-il normalement tout en refusant la copie du texte ? Parce qu’ouvrir un PDF et copier depuis un PDF sont deux permissions distinctes. Un fichier peut être lisible à l’écran tout en bloquant la copie de son contenu dans le lecteur.
3. La page contient un contenu mixte
Certains PDF sont brouillons. Une même page peut contenir du vrai texte sélectionnable dans une zone, et des captures d’écran, des schémas, des signatures ou des inserts scannés dans une autre. Cela crée un comportement déroutant : un paragraphe se copie normalement, mais le tableau juste à côté, non.
C’est courant dans les contrats, les rapports, les formulaires, les manuels et les documents professionnels exportés.
Pourquoi un texte visible n’est pas toujours sélectionnable Un texte qui paraît lisible à l’écran peut en réalité faire partie d’une image, d’une capture, d’un graphique, d’une image de vidéo ou d’un canevas d’application. S’il n’y a pas de couche de texte, le copier-coller normal ne fonctionnera pas, même si les lettres vous semblent parfaitement nettes.
Comment savoir si le PDF contient du vrai texte
Avant de vous lancer dans la conversion de fichiers ou l’installation d’un logiciel lourd, faites un diagnostic rapide.
Essayez de surligner un seul mot
Ouvrez le PDF dans Edge, Chrome ou Adobe Reader et essayez de surligner un seul mot au milieu de la page.
- si vous pouvez sélectionner des mots ou des lignes un par un, le PDF contient probablement du vrai texte ;
- si toute la page se surligne comme un seul rectangle ou une seule image, la page est probablement scannée ;
- si certaines parties se sélectionnent et d’autres non, le PDF contient sans doute un mélange de texte et d’image.
Zoomez et regardez les lettres
C’est un indice utile que beaucoup d’articles passent sous silence.
Si vous zoomez et que les lettres paraissent légèrement floues, irrégulières ou « photographiques », la page est peut-être basée sur une image. Le vrai texte reste généralement net au zoom, car il est rendu sous forme de caractères, et non étiré comme une photo.
Essayez la recherche
Appuyez sur Ctrl + F et cherchez un mot que vous voyez clairement sur la page.
- si la recherche le trouve, il y a probablement une couche de texte ;
- si la recherche ne trouve rien alors que le mot est juste là, la page est peut-être un scan ou un contenu en image uniquement.
Cela dit, un fichier peut très bien avoir une couche de texte et bloquer la copie via ses permissions. Un PDF consultable n’est donc pas automatiquement un PDF copiable.
Ce que les gens essaient en premier — et pourquoi ça échoue souvent
La plupart des gens font d’abord le geste évident. Ils ouvrent le fichier dans Edge, Chrome ou Adobe Reader et essaient de sélectionner le texte à la souris. Quand ça échoue, ils en concluent que Windows est cassé ou que le lecteur PDF est mauvais.
Et là commence le mauvais parcours.
- ils essaient une autre application PDF et obtiennent le même résultat ;
- ils envoient le document sur un convertisseur en ligne au hasard ;
- ils convertissent tout le PDF alors qu’ils n’ont besoin que d’un paragraphe ;
- ils font une capture d’écran et retapent le texte à la main ;
- ils perdent du temps à régler le mauvais problème, parce que la cause est le fichier lui-même, pas le lecteur.
Ce schéma se répète parce que le symptôme est identique d’une cause à l’autre. Un PDF verrouillé et un PDF scanné donnent tous deux l’impression que « je n’arrive pas à copier ce texte », alors que la raison est complètement différente.
C’est une distinction importante :
- PDF scanné : il n’y a aucun vrai texte à copier ;
- PDF verrouillé : il y a peut-être du vrai texte, mais le lecteur n’autorise pas la copie ;
- Image dans un PDF : seule cette partie de la page a besoin de l’OCR, pas forcément tout le document.
Les options intégrées et gratuites à essayer d’abord
Avant de passer à l’OCR, il est logique d’essayer la voie simple.
Edge, Chrome ou Adobe Reader
Si le PDF contient du vrai texte et qu’aucune restriction de copie ne vous bloque, ces lecteurs intégrés ou courants suffisent généralement. Surlignez le texte, copiez-le, et passez à la suite.
C’est la voie la moins contraignante, et la bonne quand elle fonctionne.
PDF consultable, mais copie impossible
Si le document est consultable mais que la copie échoue, le fichier est peut-être restreint. Dans ce cas, changer de lecteur n’aidera sans doute pas, car la restriction fait partie des règles du fichier.
OCR via un convertisseur complet
Si le PDF est scanné et que vous devez transformer tout le fichier en texte consultable, une chaîne OCR complète peut avoir du sens. C’est plus pertinent quand vous travaillez sur un long rapport, plusieurs pages ou des documents d’archives.
Le problème, c’est que cette approche est souvent disproportionnée pour un usage réel ordinaire. Si tout ce qu’il vous faut, c’est une adresse, une citation, un paragraphe ou un bloc tiré d’une capture intégrée au PDF, convertir le fichier entier est maladroit.
Quand l’OCR est réellement nécessaire
OCR signifie reconnaissance optique de caractères. Le procédé lit les lettres visibles d’une image et les transforme en véritable texte que vous pouvez copier.
Qu’est-ce que l’OCR ? L’OCR est le procédé qui consiste à reconnaître le texte d’une image, d’un scan, d’une capture d’écran ou d’une autre source visuelle, et à le convertir en texte modifiable et sélectionnable.
Vous avez besoin de l’OCR lorsqu’il n’existe aucune couche de texte exploitable à copier directement.
Cela inclut des cas courants comme :
- un contrat ou une lettre scannés ;
- une photo transformée en PDF ;
- un tableau ou un schéma enregistré comme image à l’intérieur du PDF ;
- un scan de bureau de mauvaise qualité ;
- une diapositive de présentation exportée en images dans un PDF ;
- du texte visible dans une image de vidéo, une capture ou une fenêtre d’application.
C’est là que beaucoup de gens perdent du temps à essayer de « déverrouiller » quelque chose qui n’est pas verrouillé du tout. Il n’y a tout simplement aucun texte à copier au départ.
Le juste milieu malin : l’OCR visuel plutôt que la conversion complète
Si votre objectif est de capturer uniquement le texte que vous voyez déjà à l’écran, l’OCR de document entier est souvent excessif.
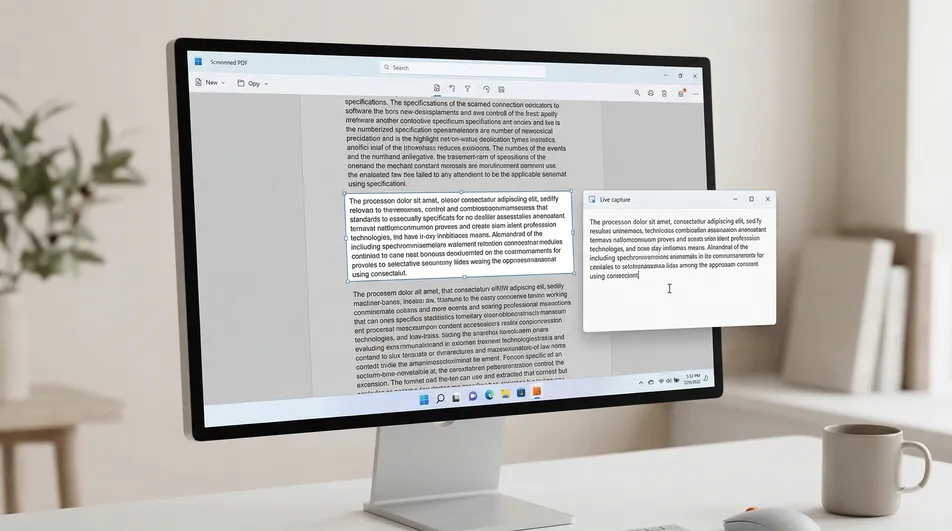
C’est là que Screenie OCR Tool trouve toute sa place. Au lieu de reconstruire tout le PDF, il extrait le texte de la zone visible que vous sélectionnez à l’écran.
Cela le rend particulièrement pratique quand :
- vous n’avez besoin que de quelques lignes, pas de tout le fichier ;
- le PDF contient une page scannée ou une capture d’écran intégrée ;
- vous copiez du texte depuis un graphique, une image ou un schéma ;
- le texte est visible dans un site, une application, une présentation ou un sous-titre de vidéo ;
- vous ne voulez pas passer par toute une chaîne de conversion PDF juste pour récupérer un petit passage.
Compte tenu de ces compromis, la décision devient simple :
- utilisez la copie intégrée quand le PDF contient du vrai texte sélectionnable ;
- utilisez l’OCR complet ou la conversion quand vous devez traiter tout le document ;
- utilisez l’OCR visuel quand le vrai travail consiste simplement à capturer vite du texte visible.
C’est pourquoi Screenie fonctionne ici comme une recommandation pratique. Il est plus simple qu’un éditeur OCR complet, plus rapide que la conversion d’un fichier entier pour un seul paragraphe, et mieux adapté aux situations du type « il me faut ce texte tout de suite ».
Comment extraire le texte d’un PDF en moins d’une minute sous Windows
Ces étapes fonctionnent particulièrement bien quand le texte est visible mais non sélectionnable.
-
Ouvrez le PDF dans votre lecteur habituel. Edge, Chrome et Adobe Reader conviennent tous. Vous n’avez pas besoin de déplacer le fichier.
-
Repérez la zone exacte dont vous avez besoin. Faites défiler jusqu’au paragraphe, à la légende, au tableau ou à la zone d’image qui contient le texte voulu.
-
Vérifiez d’abord si la copie intégrée fonctionne. Essayez de sélectionner un mot. Si le surlignage normal marche, copiez-le directement et oubliez l’OCR.
-
Passez à Screenie quand la sélection échoue. Lancez Screenie OCR Tool et activez la zone de capture.
-
Tracez un cadre autour du texte visible. Ne sélectionnez que la partie qui vous intéresse vraiment. Cela accélère généralement le traitement et garde un résultat plus propre.
-
Collez le texte extrait là où vous en avez besoin. Une fois la capture terminée, collez-le dans Word, un e-mail, des notes, une messagerie ou l’endroit où vous travaillez.
Cette approche visuelle est souvent plus rapide que d’exporter, convertir ou lancer l’OCR sur un fichier entier quand la vraie tâche est petite.
Cas particuliers utiles qui sèment la confusion
Un contrat scanné qui paraît normal
Un contrat scanné peut ressembler à un PDF numérique classique, parce que les lettres semblent assez nettes à l’écran. Mais si glisser le curseur sélectionne la page comme une seule image, l’OCR est nécessaire.
Un PDF partiellement sélectionnable
C’est un indice fort que le fichier contient un contenu mixte. Le corps du texte peut être réel, tandis que les signatures, captures, encadrés ou schémas sont en image. Dans ce cas, utilisez la copie normale là où elle fonctionne, et l’OCR uniquement là où elle échoue.
Le texte dans les graphiques, tableaux et captures
Même dans un PDF normal, le texte à l’intérieur d’éléments graphiques intégrés n’est souvent pas sélectionnable. La copie PDF standard peut fonctionner pour les paragraphes mais échouer sur les étiquettes d’un graphique. Un outil OCR visuel est généralement mieux adapté à cette zone.
Les scans à basse résolution
L’OCR n’est pas magique. Si la source est floue, de travers, fortement compressée ou peu contrastée, la précision de reconnaissance peut chuter. Ce n’est pas seulement une affaire d’outil : c’est aussi une affaire de qualité de la source.
Les mises en page sur plusieurs colonnes
Certaines chaînes OCR s’embrouillent quand une page comporte des colonnes étroites, des notes en marge ou des éléments visuels qui se chevauchent. Sélectionner une zone plus petite plutôt que toute la page donne souvent un résultat plus propre.
Ce dernier point compte plus qu’on ne le croit. Convertir tout le PDF n’est pas toujours plus malin. Quand la mise en page est compliquée, ne récupérer que la section visible qui vous intéresse peut produire de meilleurs résultats concrets.
Dépannage : si l’extraction reste brouillonne
Si vous obtenez un texte médiocre ou incomplet, le fichier n’est peut-être pas le seul en cause. Essayez ces vérifications.
Les lettres paraissent floues
Zoomez. Si le scan est flou, la précision de l’OCR en souffre généralement. Un niveau de zoom plus net ou une zone de capture plus serrée peut aider.
La page contient un contenu mixte
Ne capturez pas toute la page si seul un encadré ou un paragraphe compte. Extraire une zone plus petite réduit souvent la confusion.
La mise en page comporte des colonnes ou des notes en marge
Récupérez une colonne ou une section à la fois plutôt que de tenter l’OCR de toute la page en une seule passe.
Le PDF semble verrouillé
Si vous pouvez chercher le texte mais pas le copier, le fichier est peut-être restreint plutôt que scanné. Dans ce cas, l’OCR visuel reste souvent le contournement le plus rapide pour de petites extractions.
Vous n’avez besoin que d’une courte citation
Ne perdez pas de temps à convertir tout le document. C’est exactement le genre de situation où un OCR visuel ciblé a plus de sens qu’une chaîne PDF complète.
Quand un outil OCR complet est plus adapté
Pour rester honnête : Screenie n’est pas la réponse à tous les problèmes de PDF.
Un éditeur OCR complet ou une chaîne OCR de document peut être plus adapté quand :
- vous devez convertir tout le PDF en document consultable ;
- vous traitez de nombreuses pages d’un coup ;
- vous avez besoin de fonctions d’édition, d’annotation ou de reconstruction de fichier ;
- vous voulez préserver la structure du document sur l’ensemble du fichier.
Mais ce n’est pas le même travail que de récupérer vite le texte d’une seule zone visible.
Cet article porte vraiment sur une frustration courante et concrète : le texte est à l’écran, mais la copie normale ne marche pas. Pour ce problème précis, un OCR visuel est souvent la solution la plus propre.
Vous pouvez aussi explorer d’autres guides Windows pratiques sur le blog RoxyApps si vous rencontrez des problèmes similaires de PDF, de capture d’écran ou d’extraction de texte. Et si votre objectif final est de retravailler le document, voyez notre guide pour convertir un PDF en Word.
FAQ
Pourquoi je n’arrive pas à copier le texte d’un PDF alors que je le lis clairement ?
Parce qu’un texte lisible à l’écran n’est pas toujours du vrai texte sélectionnable. La page peut être un scan, une image intégrée ou un contenu assorti de restrictions de copie.
Comment savoir si un PDF est scanné ou textuel ?
Essayez de surligner un seul mot et utilisez la recherche Ctrl + F. Si toute la page se comporte comme une image ou si la recherche ne trouve pas des mots pourtant visibles, le PDF est probablement scanné ou en image.
Un PDF verrouillé et un PDF scanné peuvent-ils donner la même impression ?
Oui. Les deux produisent le même symptôme : impossible de copier le texte. La différence, c’est qu’un PDF scanné n’a pas de couche de texte, tandis qu’un PDF verrouillé peut contenir du vrai texte mais en bloquer la copie via ses permissions.
Quelle est la façon la plus rapide d’extraire le texte d’un PDF scanné sous Windows ?
Si vous devez convertir tout le document, une chaîne OCR complète peut convenir. Si vous n’avez besoin que d’une section visible rapidement, un outil OCR visuel comme Screenie est généralement plus rapide et plus simple.
L’OCR ne fonctionne-t-il que pour les PDF ?
Non. L’OCR peut aussi extraire le texte de captures d’écran, d’images scannées, de graphiques, d’applications, de sites, de présentations et même de sous-titres de vidéo, du moment que le texte est visible à l’écran.
Pourquoi seule une partie de mon PDF se laisse-t-elle copier ?
Cela signifie généralement que le fichier contient un contenu mixte. Certaines sections sont du vrai texte, tandis que d’autres sont des captures, des scans ou des graphiques intégrés qui réclament l’OCR.
« PDF OCR » est-il un type de PDF particulier ?
Pas vraiment. On désigne en général un PDF auquel l’OCR a été appliqué pour que le texte en image devienne consultable ou extractible. C’est la description d’un traitement, pas une espèce de PDF à part.
Faut-il convertir tout le PDF si je n’ai besoin que d’un paragraphe ?
Généralement non. La conversion de tout le document est souvent inutile quand votre vrai objectif est de capturer un paragraphe visible, une cellule de tableau, une légende ou une zone de capture.
Peut-on extraire le texte d’un PDF verrouillé sans reconstruire tout le fichier ?
Pour une petite section visible, oui. Un OCR visuel permet souvent de récupérer le texte voulu sans vous imposer une conversion complète du document.
Sources
- Copier du contenu depuis des PDF (aide Adobe Reader)
- Numériser des documents en PDF et reconnaître le texte (aide Adobe Acrobat)
- OCR PDF en texte (iLovePDF) : ilovepdf.com/fr/ocr-pdf
En résumé
Quand vous n’arrivez pas à copier le texte d’un PDF sous Windows, le coupable n’est presque jamais Windows lui-même. C’est la nature du fichier : un scan sans couche de texte, un document verrouillé, ou une page au contenu mixte qui mélange vrai texte et images.
Le bon réflexe est de diagnostiquer avant d’agir. Essayez de surligner un mot, lancez une recherche, zoomez sur les lettres. Vous saurez alors si vous avez affaire à du vrai texte, à un scan ou à une restriction — et donc s’il faut une simple copie ou l’OCR.
Pour un document entier, un OCR complet a sa place. Mais pour la situation la plus fréquente — « le texte est là, sous mes yeux, et il refuse de se copier » — un OCR visuel comme Screenie OCR Tool reste la solution la plus rapide et la plus propre : vous sélectionnez la zone visible, et vous récupérez le texte, sans reconstruire tout le PDF.