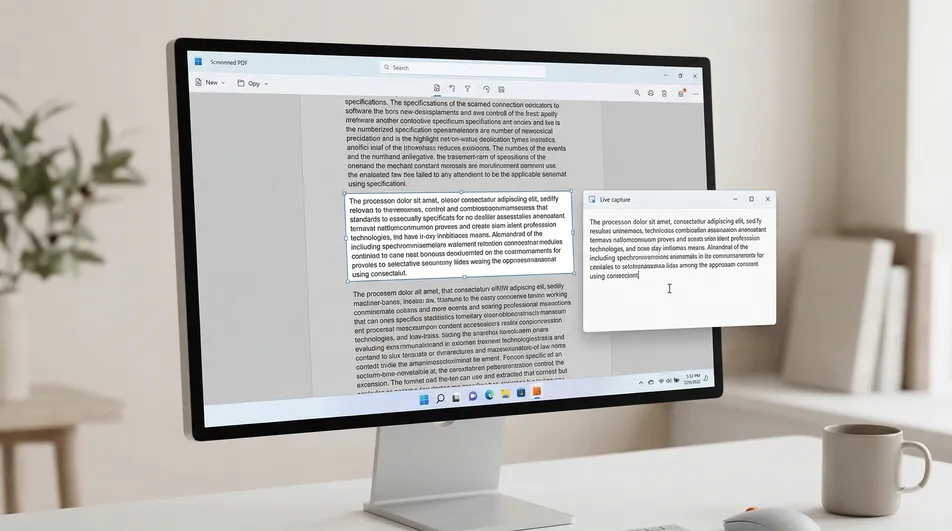
El problema del PDF “no seleccionable”
Las palabras están ahí mismo, en la página, pero el cursor no las resalta. Arrastras por encima de una frase y, o no pasa nada, o se selecciona la página entera como si fuera una imagen plana. En la mayoría de los casos, el problema no es Windows en absoluto. Es la forma en que se creó el PDF.
Un PDF no es automáticamente un documento de texto de verdad. Algunos PDF contienen una capa de texto real que puedes seleccionar, buscar y copiar. Otros son solo imágenes envueltas en un contenedor PDF. Y otros contienen texto normal, pero quien lo creó añadió restricciones de copia que impiden que tu lector te deje copiarlo.
Esa distinción importa porque copiar texto y extraer texto con OCR no son el mismo flujo de trabajo.
Respuesta rápida: si el texto de un PDF es real y seleccionable, los visores integrados como Edge, Chrome o Adobe Reader suelen bastar. Si la página se comporta como una sola imagen, hace falta OCR. Si el texto parece normal pero aun así se niega a copiarse, puede que el archivo tenga restricciones de copia. Para extraer rápido solo el texto visible, la vía gratuita más práctica es probar primero la selección integrada. La vía más ágil es usar una herramienta de OCR visual como Screenie OCR Text Recognition Tool, que captura el texto directamente de lo que ya ves en pantalla.
📊 Comparativa: las mejores formas de extraer texto
| Método | ¿Sirve para PDF de texto normal? | ¿Sirve para PDF escaneados? | Ideal para | Principal concesión |
|---|---|---|---|---|
| Edge / Chrome / Adobe Reader | ✅ Sí | ❌ No | Copiar rápido de PDF con texto real | Falla cuando no hay capa de texto o la copia está restringida |
| OCR online / conversores de PDF | ✅ Sí | ✅ Sí | Conversión de todo el documento | Paso de subida, fricción extra, a menudo demasiado trabajo para un párrafo |
| Editores con OCR completo o suites de PDF | ✅ Sí | ✅ Sí | Edición intensiva o flujos de documento completo | Más configuración y complejidad de la que mucha gente necesita |
| Screenie (OCR visual) | ✅ Sí | ✅ Sí | Coger rápido el texto visible de la pantalla | Lo mejor cuando necesitas una zona concreta, no rehacer todo el PDF |
La versión honesta es sencilla. Los visores integrados merecen su crédito: son la mejor opción cuando el archivo ya contiene texto real. Las herramientas de OCR online pueden resultar cómodas cuando de verdad necesitas procesar un documento entero. Los editores con OCR completo pueden ser potentes para flujos de trabajo más grandes. Pero cuando tu situación real es “solo necesito este bloque de texto visible ahora mismo”, una herramienta de OCR visual suele ser el punto intermedio más inteligente.
Qué te impide realmente copiar el texto
Si no puedes copiar el texto de un PDF en Windows, suele deberse a una de estas tres cosas.
1. El PDF es en realidad un escaneo
Un PDF escaneado a menudo es solo una imagen dentro de un archivo PDF. La página puede verse perfectamente legible, pero tu equipo no está viendo palabras. Está viendo píxeles.
Por eso, al arrastrar el cursor, puede que se seleccione la página entera como un gran bloque en lugar de palabra por palabra. Es una de las señales más claras de que el archivo no tiene una capa de texto real.
¿Qué es un PDF escaneado? Un PDF escaneado es un documento donde cada página se guarda como una imagen en vez de como texto seleccionable. Puede parecer un PDF normal, pero la copia falla porque no hay caracteres reales bajo la imagen de la página.
2. El PDF tiene restricciones de copia
Los archivos PDF pueden incluir permisos que limitan lo que el lector te deja hacer. Una restricción habitual es desactivar la copia de texto.
En ese caso, el texto puede ser real y legible, pero el programa obedece las reglas del archivo y se niega a copiarlo.
¿Por qué un PDF puede abrirse con normalidad y aun así no dejarte copiar el texto? Porque abrir un PDF y copiar de un PDF son permisos distintos. Un archivo puede ser legible en pantalla y, a la vez, bloquear la copia de contenido dentro del visor.
3. La página contiene contenido mixto
Algunos PDF son un caos. Una misma página puede contener texto real y seleccionable en una sección y capturas de pantalla incrustadas, diagramas, firmas o insertos escaneados en otra. Eso genera un comportamiento confuso: un párrafo se copia con normalidad, pero la tabla de al lado no.
Es algo habitual en contratos, informes, formularios, manuales y documentos de empresa exportados.
Por qué el texto visible no siempre es seleccionable El texto que parece legible en pantalla puede ser, en realidad, parte de una imagen, una captura, un gráfico, un fotograma de vídeo o un lienzo de una aplicación. Si no hay capa de texto, copiar y pegar normales no funcionarán, aunque las letras se vean nítidas para ti.
Cómo saber si el PDF contiene texto real
Antes de ponerte a convertir archivos o instalar programas pesados, haz un diagnóstico rápido.
Intenta resaltar una palabra
Abre el PDF en Edge, Chrome o Adobe Reader e intenta resaltar una sola palabra en mitad de la página.
- Si puedes seleccionar palabras o líneas sueltas, el PDF probablemente contiene texto real.
- Si se resalta la página entera como un rectángulo o una imagen, la página probablemente está escaneada.
- Si algunas partes se seleccionan y otras no, lo más probable es que el PDF contenga texto e imagen mezclados.
Amplía y mira las letras
Esta es una pista de experto que muchos artículos se saltan.
Si amplías y las letras se ven algo borrosas, irregulares o como de foto, puede que la página esté basada en imagen. El texto real suele mantenerse nítido al ampliar porque se renderiza como caracteres, no estirado como una imagen.
Prueba la búsqueda
Pulsa Ctrl + F y busca una palabra que veas claramente en la página.
- Si la búsqueda la encuentra, probablemente hay una capa de texto.
- Si la búsqueda no encuentra nada aunque la palabra esté ahí mismo, la página puede ser un escaneo o contenido solo de imagen.
Dicho esto, un archivo puede tener capa de texto y aun así bloquear la copia mediante permisos. Así que un PDF en el que se puede buscar no es automáticamente un PDF del que se puede copiar.
Lo que la gente suele probar primero, y por qué falla a menudo
Casi todo el mundo hace lo obvio primero. Abre el archivo en Edge, Chrome o Adobe Reader e intenta seleccionar el texto arrastrando. Cuando eso falla, da por hecho que Windows está estropeado o que el visor de PDF es malo.
Y entonces empieza el mal camino.
- Prueban otra app de PDF y obtienen el mismo resultado.
- Suben el documento a un conversor online cualquiera.
- Convierten el PDF entero aunque solo necesiten un párrafo.
- Hacen una captura de pantalla y vuelven a teclear el texto a mano.
- Pierden tiempo arreglando el problema equivocado, porque la cuestión es el propio archivo, no el lector.
Ese patrón ocurre porque el síntoma es el mismo ante causas distintas. Un PDF bloqueado y un PDF escaneado pueden sentirse igual de “no puedo copiar este texto”, pero el motivo es completamente diferente.
Es una distinción importante:
- PDF escaneado: no hay texto real que copiar.
- PDF bloqueado: puede haber texto real, pero el visor no permite la copia.
- Imagen dentro de un PDF: solo esa parte de la página necesita OCR, no necesariamente todo el documento.
Opciones integradas y gratuitas que vale la pena probar primero
Antes de saltar al OCR, tiene sentido probar la vía sencilla.
Edge, Chrome o Adobe Reader
Si el PDF contiene texto real y ninguna restricción de copia te lo impide, estos visores integrados o habituales suelen bastar. Resalta el texto, cópialo y a otra cosa.
Es la vía con menos fricción y la correcta cuando funciona.
PDF con búsqueda activa pero la copia sigue fallando
Si en el documento se puede buscar pero la copia falla, puede que el archivo esté restringido. En ese caso, cambiar de visor quizá no ayude, porque la restricción forma parte de las reglas del archivo.
OCR a través de un conversor completo
Si el PDF está escaneado y necesitas convertir todo el archivo en texto con búsqueda, un flujo de OCR completo puede tener sentido. Esto es más relevante cuando trabajas con un informe largo, varias páginas o documentos de archivo.
El problema es que este enfoque suele ser desproporcionado para el uso normal del día a día. Si lo único que necesitas es una dirección, una cita, un párrafo o un bloque de una captura incrustada en el PDF, convertir el archivo entero es aparatoso.
Cuándo hace falta OCR de verdad
OCR significa reconocimiento óptico de caracteres (Optical Character Recognition). Lee las letras visibles de una imagen y las convierte en texto real que puedes copiar.
¿Qué es el OCR? El OCR es el proceso de reconocer texto a partir de una imagen, un escaneo, una captura de pantalla u otra fuente visual y convertirlo en texto editable y seleccionable.
Necesitas OCR cuando no hay una capa de texto utilizable de la que copiar directamente.
Eso incluye casos habituales como:
- un contrato o una carta escaneados
- una foto convertida en PDF
- una tabla o un diagrama guardados como imagen dentro del PDF
- un escaneo de oficina de baja calidad
- una diapositiva de presentación exportada a PDF como imágenes
- texto visible en un fotograma de vídeo, una captura o la ventana de una aplicación
Aquí es donde mucha gente pierde el tiempo intentando “desbloquear” algo que no está bloqueado en absoluto. Sencillamente, no hay texto ahí que copiar de entrada.
El punto intermedio inteligente: OCR visual en lugar de conversión completa
Si tu objetivo es capturar solo el texto que ya ves en pantalla, hacer OCR de todo el documento suele ser excesivo.
Ahí es donde Screenie OCR Text Recognition Tool encaja bien. En lugar de reconstruir todo el PDF, extrae el texto de la zona visible que seleccionas en pantalla.
Eso lo hace especialmente práctico cuando:
- solo necesitas unas líneas, no el archivo entero
- el PDF contiene una página escaneada o una captura incrustada
- estás copiando texto de un gráfico, una imagen o un diagrama
- el texto se ve en una web, una app, una presentación o el subtítulo de un vídeo
- no quieres pasar por todo un flujo de conversión de PDF solo para extraer un pasaje pequeño
Teniendo en cuenta estas concesiones, la decisión se vuelve sencilla:
- Usa la copia integrada cuando el PDF contiene texto real y seleccionable.
- Usa OCR completo o conversión cuando necesitas un procesamiento de todo el documento.
- Usa OCR visual cuando la tarea real es simplemente capturar texto visible rápido.
Por eso Screenie funciona como recomendación práctica aquí. Es más sencillo que un editor de OCR completo, más rápido que convertir un archivo entero por un párrafo y más adecuado para situaciones de “necesito este texto ahora mismo”.
Cómo extraer texto de un PDF en Windows en menos de un minuto
Estos pasos funcionan especialmente bien cuando el texto es visible pero no seleccionable.
-
Abre el PDF en tu visor habitual. Edge, Chrome y Adobe Reader sirven todos. No necesitas mover el archivo a ningún sitio.
-
Localiza la zona exacta que necesitas. Desplázate hasta el párrafo, el pie, la tabla o el área de imagen que contiene el texto que quieres.
-
Comprueba primero si funciona la copia integrada. Intenta seleccionar una palabra. Si el resaltado normal funciona, cópiala directamente y sáltate el OCR.
-
Usa Screenie cuando la selección falla. Abre Screenie OCR Text Recognition Tool y activa el área de captura.
-
Dibuja un recuadro alrededor del texto visible. Selecciona solo la parte que de verdad necesitas. Esto suele mejorar la velocidad y deja el resultado más limpio.
-
Pega el texto extraído donde lo necesites. Una vez completada la captura, pégalo en Word, el correo, las notas, Slack o donde estés trabajando.
Este enfoque visual suele ser más rápido que exportar, convertir o hacer OCR de un archivo entero cuando la tarea real es pequeña.
Casos límite muy útiles que confunden a la gente
Un contrato escaneado que parece normal
Un contrato escaneado puede parecer un PDF digital normal porque las letras se ven bastante nítidas en pantalla. Pero si al arrastrar el cursor se selecciona la página como una sola imagen, hace falta OCR.
Un PDF que solo se deja seleccionar en parte
Es una pista clara de que el archivo contiene contenido mixto. El cuerpo del texto puede ser real, mientras que firmas, capturas, barras laterales o diagramas están basados en imagen. En ese caso, usa la copia normal donde funcione y OCR solo donde no.
Texto dentro de gráficos, tablas y capturas
Incluso en un PDF normal, el texto dentro de imágenes incrustadas a menudo no es seleccionable. La copia estándar de PDF puede funcionar para los párrafos pero fallar con las etiquetas dentro del gráfico. Una herramienta de OCR visual suele encajar mejor para esa zona.
Escaneos de baja resolución
El OCR no es magia. Si la fuente está borrosa, torcida, muy comprimida o con poco contraste, la precisión del reconocimiento puede bajar. Esto no depende solo de la herramienta; también de la calidad de origen.
Diseños a varias columnas
Algunos flujos de OCR pueden liarse cuando una página tiene columnas estrechas, notas al margen o elementos visuales superpuestos. Seleccionar una zona más pequeña en lugar de la página entera suele dar un resultado más limpio.
Ese último punto importa más de lo que la gente cree. Convertir todo el PDF no siempre es lo más inteligente. Cuando el diseño es complicado, extraer solo la sección visible que te interesa puede dar mejores resultados en la práctica.
Solución de problemas: si la extracción sigue saliendo regular
Si obtienes un texto pobre o incompleto, puede que el archivo no sea el único problema. Prueba estas comprobaciones.
Las letras se ven borrosas
Amplía. Si el escaneo está difuso, la precisión del OCR suele resentirse. Un nivel de zoom más limpio o un área de captura más ajustada pueden ayudar.
La página tiene contenido mixto
No captures la página entera si solo importa un recuadro o un párrafo. Coger una zona más pequeña suele reducir la confusión.
El diseño tiene columnas o notas al margen
Coge una columna o una sección cada vez en lugar de intentar hacer OCR de toda la página de una pasada.
El PDF parece bloqueado
Si puedes buscar el texto pero no copiarlo, puede que el archivo esté restringido en lugar de escaneado. En ese caso, un enfoque de OCR visual sigue siendo el atajo más rápido para trabajos pequeños de extracción.
Solo necesitas una cita corta
No pierdas tiempo convertiendo el documento entero. Esta es exactamente la clase de situación donde el OCR visual dirigido tiene más sentido que todo un flujo de PDF.
Cuándo tiene más sentido una herramienta de OCR completa
Para ser honestos: Screenie no es la respuesta a todos los problemas de PDF.
Un editor de OCR completo o un flujo de OCR de documentos puede encajar mejor cuando:
- necesitas convertir todo el PDF en un documento con búsqueda
- estás procesando muchas páginas a la vez
- necesitas funciones de edición, anotación o reconstrucción del archivo
- quieres conservar la estructura del documento en todo el archivo
Pero eso no es la misma tarea que sacar rápido el texto de una zona visible.
Este artículo trata, en realidad, de una frustración común y práctica: el texto está en tu pantalla, pero la copia normal no funciona. Para ese problema exacto, un flujo de OCR visual suele ser la solución más limpia.
También puedes explorar otras guías prácticas para Windows en el blog de RoxyApps si te enfrentas a problemas parecidos de PDF, capturas o extracción de texto.
Preguntas frecuentes (FAQ)
¿Por qué no puedo copiar el texto de un PDF si lo leo perfectamente?
Porque el texto que se lee en pantalla no siempre es texto real y seleccionable. La página puede ser un escaneo, una imagen incrustada o contenido con restricciones de copia.
¿Cómo sé si un PDF está escaneado o es de texto?
Intenta resaltar una palabra y usa la búsqueda con Ctrl + F. Si la página entera se comporta como una sola imagen o la búsqueda no encuentra palabras que ves claramente, lo más probable es que el PDF esté escaneado o sea de imagen.
¿Un PDF bloqueado y uno escaneado pueden sentirse igual?
Sí. Ambos pueden producir el mismo síntoma: no puedes copiar el texto. La diferencia es que un PDF escaneado no tiene capa de texto, mientras que un PDF bloqueado puede contener texto real pero bloquear la copia mediante permisos.
¿Cuál es la forma más rápida de extraer texto de un PDF escaneado en Windows?
Si necesitas convertir el documento entero, un flujo de OCR completo puede ser lo apropiado. Si solo necesitas una sección visible rápido, una herramienta de OCR visual como Screenie suele ser más rápida y sencilla.
¿El OCR funciona solo para PDF?
No. El OCR también puede extraer texto de capturas de pantalla, imágenes escaneadas, gráficos, aplicaciones, webs, presentaciones e incluso subtítulos de vídeo, siempre que el texto sea visible en pantalla.
¿Por qué solo una parte de mi PDF me deja copiar el texto?
Eso suele significar que el archivo contiene contenido mixto. Algunas secciones pueden ser texto real, mientras que otras son capturas, escaneos o gráficos incrustados que requieren OCR.
¿“PDF con OCR” es un tipo especial de PDF?
En realidad no. La gente suele referirse a un PDF al que se le ha aplicado OCR para que el texto basado en imagen se vuelva buscable o extraíble. Es la descripción de un flujo de trabajo, no una especie de PDF aparte.
¿Hace falta convertir todo el PDF si solo necesito un párrafo?
Normalmente no. Convertir todo el documento suele ser innecesario cuando tu objetivo real es capturar un párrafo, una celda de tabla, un pie o la zona de una captura que ya ves.
¿Puedo extraer texto de un PDF bloqueado sin reconstruir todo el archivo?
Para una sección visible pequeña, sí. Un flujo de OCR visual a menudo consigue el texto que necesitas sin obligarte a un proceso de conversión de todo el documento.