「选不中」的 PDF 难题
文字明明就在页面上,光标却怎么也选不中。你拖着鼠标划过一句话,要么什么都没发生,要么整页像一张平铺的图片一样被一起选中。多数情况下,问题根本不在 Windows,而在于这个 PDF 是怎么做出来的。
PDF 并不会自动就是一份「真正的文字文档」。有些 PDF 里含有可以选中、检索、复制的真实文字层;有些只是套在 PDF 容器里的图片;还有一些含有正常文字,但制作者加了复制限制,不让你的阅读器把文字取出来。
这个区别很重要,因为复制文字和用 OCR 提取文字,根本不是同一套流程。
先说结论: 如果 PDF 里的文字是真实、可选中的,Edge、Chrome、Adobe Reader 这类自带阅读器通常就够用了。如果整页像一张图片一样,就需要 OCR。如果文字看着正常却仍然复制不了,这个文件可能加了复制限制。要快速取出看得见的文字,最实用的免费做法是先试试自带的选中复制。而最省事的路径,是用 Screenie OCR Text Recognition Tool 这类可视化 OCR 工具——它直接从你屏幕上已经看到的画面里把文字抓出来。
📊 对比:提取文字的几种方式
| 方式 | 适用于普通文字版 PDF? | 适用于扫描件 PDF? | 适合场景 | 主要取舍 |
|---|---|---|---|---|
| Edge / Chrome / Adobe Reader | ✅ 可以 | ❌ 不行 | 从真实文字版 PDF 里快速复制 | 没有文字层、或复制被限制时就无能为力 |
| 在线 OCR/PDF 转换工具 | ✅ 可以 | ✅ 可以 | 整份文档的转换 | 要先上传、流程繁琐,为了一段文字往往太费事 |
| 完整 OCR 编辑器或 PDF 套件 | ✅ 可以 | ✅ 可以 | 重度编辑或整份文档的处理 | 设置和复杂度,比很多人实际需要的高 |
| Screenie(可视化 OCR) | ✅ 可以 | ✅ 可以 | 快速抓取屏幕上看得见的文字 | 最适合只要某个区域、而非重建整份 PDF 的情况 |
说句实在话,其实很简单。自带阅读器值得肯定:当文件本身就含有真实文字时,它是最佳选择。在线 OCR 工具在你确实需要处理整份文档时很方便。完整 OCR 编辑器在更大的工作流里很强大。但当你的真实处境是「我现在只要这一块看得见的文字」时,可视化 OCR 工具往往是最聪明的折中。
到底是什么让你复制不了文字
如果你在 Windows 上没法从 PDF 里复制文字,通常是下面三种原因之一。
1. 这个 PDF 其实是扫描件
扫描件 PDF 往往只是一个 PDF 文件里装着的一张图片。页面看起来清清楚楚,可你的电脑看到的并不是文字,而是像素。
这就是为什么拖动光标时,整页会被当作一大块一起选中,而不是一个词一个词地选。这是文件没有真实文字层最明显的信号之一。
什么是扫描件 PDF? 扫描件 PDF 是指每一页都以图片、而非可选中文字的形式保存的文档。它看上去可能和普通 PDF 一样,但复制会失败,因为页面图像底下根本没有真实的字符。
2. 这个 PDF 加了复制限制
PDF 文件可以包含权限设置,限制阅读器允许你做什么。一种常见的限制,就是禁止复制文字。
这种情况下,文字可能是真实、可读的,但软件遵守文件的规则,拒绝把它复制出来。
为什么一个 PDF 能正常打开,却不让你复制文字? 因为「打开 PDF」和「从 PDF 复制」是两种不同的权限。一个文件可以在屏幕上正常阅读,同时在阅读器内部仍然禁止复制内容。
3. 这一页是图文混排
有些 PDF 内容很杂。同一页里,某一部分是真实可选中的文字,另一部分却嵌着截图、示意图、签名或扫描插页。这就造成了让人困惑的现象:一个段落能正常复制,旁边的表格却不行。
这在合同、报告、表单、说明书,以及导出的商务文档里很常见。
为什么看得见的文字不一定能选中 屏幕上看着可读的文字,实际上可能是图片、截图、图表、视频画面或应用画布的一部分。只要没有文字层,普通的复制粘贴就用不了——哪怕这些字在你看来清清楚楚。
怎么判断 PDF 里有没有真实文字
在你动手转换文件、或安装笨重的软件之前,先做一个快速诊断。
试着选中一个词
在 Edge、Chrome 或 Adobe Reader 里打开 PDF,试着选中页面中间的某一个词。
- 如果你能选中单个的词或行,这个 PDF 多半含有真实文字。
- 如果整页像一个矩形或一张图片那样被一起高亮,这一页多半是扫描件。
- 如果有些部分能选中、有些不能,这个 PDF 很可能是图文混排。
放大看看那些字
这是一条很多文章会跳过、但很实用的内行线索。
如果你放大后,发现字母略微发虚、不齐整、或带点照片感,这一页可能是基于图片的。真实文字在放大时通常依然清晰,因为它是作为字符被渲染出来的,而不是像图片那样被拉伸。
试试搜索
按 Ctrl + F,搜索一个你在页面上清楚看到的词。
- 如果搜得到,多半是有文字层的。
- 如果那个词明明就在那儿、却搜不到,这一页可能是扫描件或纯图片内容。
话说回来,一个文件也可能既有文字层、又通过权限禁止了复制。所以「能搜索的 PDF」并不自动等于「能复制的 PDF」。
大家通常先试什么——以及为什么常常没用
多数人会先做那件最顺手的事:在 Edge、Chrome 或 Adobe Reader 里打开文件,试着拖动选中文字。一旦失败,就以为是 Windows 出了问题,或者 PDF 阅读器太差。
接着,弯路就开始了。
- 换一个 PDF 应用,结果还是一样。
- 把文档上传到某个随便搜到的在线转换工具。
- 明明只要一段,却把整个 PDF 都转换了。
- 截个图,然后手动把文字重新打一遍。
- 把时间浪费在解决错误的问题上——因为症结是文件本身,而不是阅读器。
之所以会陷入这种套路,是因为不同的原因表现出同样的症状。一个受限制的 PDF 和一个扫描件 PDF,都会让人觉得「我复制不了这段文字」,但背后的原因完全不同。
这是一个重要的区别:
- 扫描件 PDF: 根本没有可复制的真实文字。
- 受限制的 PDF: 可能有真实文字,但阅读器不允许复制。
- PDF 里的图片: 只有那一部分需要 OCR,未必是整份文档。
值得先试的自带与免费选项
在跳到 OCR 之前,先走简单路线是合理的。
Edge、Chrome 或 Adobe Reader
如果 PDF 含有真实文字、又没有复制限制挡着你,这些自带或常见的阅读器通常就够了。选中文字、复制,然后接着干活。
这是阻力最小的路线,能用时它就是对的那个。
能搜索却仍复制失败
如果文档能搜索、复制却失败,那这个文件可能加了限制。这种情况下,换阅读器也未必有用,因为限制是文件规则的一部分。
用完整转换工具做 OCR
如果 PDF 是扫描件,而你需要把整个文件变成可检索的文字,走一遍完整的 OCR 流程是说得通的。当你处理的是长篇报告、多个页面或存档文档时,这条路更对口。
问题在于,对日常的实际需求来说,这个办法往往太重了。如果你要的不过是一个地址、一句话、一个段落,或是 PDF 里某张截图上的一块文字,把整个文件都转换一遍就显得很笨拙。
什么时候真的需要 OCR
OCR 是 Optical Character Recognition(光学字符识别)的缩写。它从图片里读出看得见的字母,再把它们变成你能复制的真实文字。
什么是 OCR? OCR 是从图片、扫描件、截图或其他视觉来源中识别文字,并把它转换成可编辑、可选中文字的过程。
当没有可直接复制的可用文字层时,你就需要 OCR。
这包括一些常见情况:
- 扫描的合同或信件
- 拍照后转成的 PDF
- 以图片形式存在 PDF 里的表格或示意图
- 画质不佳的办公扫描件
- 以图片形式导出到 PDF 里的演示幻灯片
- 出现在视频画面、截图或应用窗口里的文字
很多人就是在这一步浪费了时间,试图去「解锁」一个根本没被锁的东西。其实那里压根就没有可复制的文字。
聪明的折中:用可视化 OCR,而非整份转换
如果你的目标只是抓取屏幕上已经看得见的文字,对整份文档做 OCR 往往是杀鸡用牛刀。
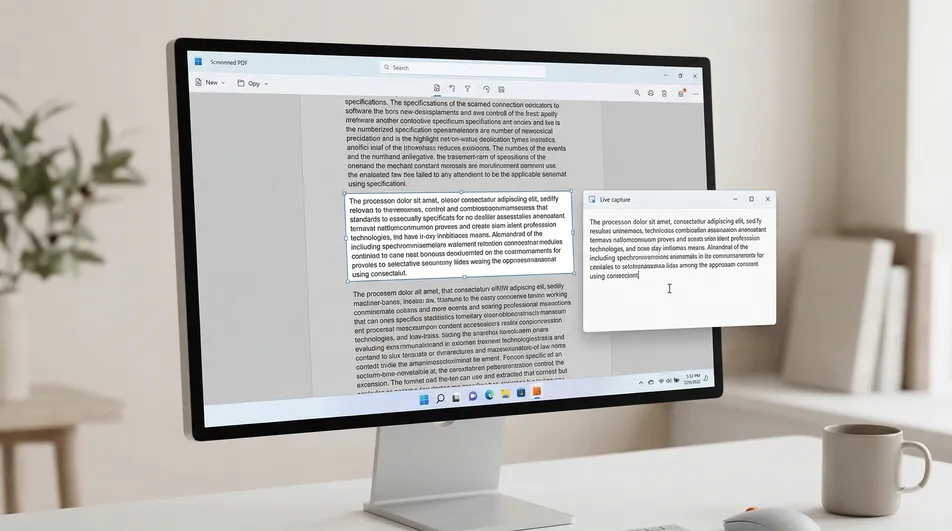
这正是 Screenie OCR Text Recognition Tool 的用武之地。它不去重建整个 PDF,而是从你在屏幕上框选的可见区域里提取文字。
所以在这些时候,它格外实用:
- 你只要几行,而不是整个文件
- PDF 里只有一页扫描件,或一张嵌入的截图
- 你要从图表、图片或示意图里复制文字
- 文字出现在网页、应用、演示文稿或视频字幕里
- 你不想为了一小段文字,去走一遍完整的 PDF 转换流程
权衡下来,决定其实很清楚:
- 用自带复制——当 PDF 含有真实、可选中的文字。
- 用完整 OCR 或转换——当你需要对整份文档做处理。
- 用可视化 OCR——当真正的任务只是快速抓取看得见的文字。
这就是为什么 Screenie 在这里是个实用的推荐。它比完整 OCR 编辑器更简单,比为一段文字转换整个文件更快,也更契合「我现在就要这段文字」的场景。
一分钟内从 PDF 里提取文字的方法
下面这些步骤,在「文字看得见却选不中」时尤其好用。
-
用你常用的阅读器打开 PDF。 Edge、Chrome、Adobe Reader 都行。文件不用挪到任何别的地方。
-
找到你需要的确切区域。 滚动到包含目标文字的那个段落、图注、表格或图片区域。
-
先试试自带复制能不能用。 选中一个词试试。如果普通高亮能用,就直接复制,跳过 OCR。
-
选中失败时用 Screenie。 启动 Screenie OCR Text Recognition Tool,激活截取区域。
-
框住看得见的文字。 只选你真正需要的那部分。这通常能提速,也让结果更干净。
-
把提取出的文字粘贴到需要的地方。 截取完成后,粘贴到 Word、邮件、笔记、Slack,或你正在用的任何地方。
当真正的任务很小的时候,这种可视化的办法,往往比导出、转换、或对整个文件做 OCR 更快。
让人困惑的高频特殊情况
看着很正常的扫描合同
扫描的合同可能看上去就像一份普通的数字 PDF,因为屏幕上的字够清晰。但只要拖动光标时整页像一张图片那样被选中,就需要 OCR。
一部分能选中的 PDF
这是文件图文混排的有力线索。正文可能是真实文字,而签名、截图、侧栏或示意图却是基于图片的。这种情况下,能用的地方就用普通复制,只在不能用的地方用 OCR。
图表、表格、截图里的文字
哪怕在一份正常的 PDF 里,嵌入图形内部的文字往往也选不中。标准的 PDF 复制对段落或许有用,对图表里的标签却会失败。对那块区域,可视化 OCR 工具通常更合适。
低分辨率扫描件
OCR 不是魔法。如果原件发虚、歪斜、压缩得厉害或对比度很低,识别准确率会下降。这不仅关乎工具,也关乎原件质量。
多栏版面
当一页里有窄栏、侧注或互相重叠的视觉元素时,有些 OCR 流程会处理得很乱。与其对整页做 OCR,不如框选更小的区域,往往能得到更干净的结果。
最后这一点,比多数人意识到的更重要。把整个 PDF 都转换,并不总是更聪明的做法。当版面很复杂时,只抓取你在意的那一小块可见内容,反而能带来更好的实际效果。
故障排查:如果提取结果仍然很乱
如果你拿到的文字很差或不完整,问题未必只出在文件上。试试这些检查。
字母看着发虚
放大看看。如果扫描本身就模糊,OCR 准确率通常会受影响。换一个更清晰的缩放级别,或框得更紧一点,都会有帮助。
这一页是图文混排
如果只有某个框或某个段落要紧,就别截取整页。抓取更小的区域,往往能减少混乱。
版面有分栏或侧注
一次抓一栏、或一节,而不是想一口气把整页都 OCR 掉。
PDF 像是被锁住了
如果你能搜索文字、却复制不了,这个文件可能是受限制、而非扫描件。这种情况下,对小段提取来说,可视化 OCR 仍然是更快的变通办法。
你只要一句短引文
别浪费时间去转换整份文档。这正是「针对性可视化 OCR 比完整 PDF 流程更合适」的典型场景。
什么时候完整 OCR 工具更合适
说句公道话:Screenie 并不是每一个 PDF 问题的答案。
在这些时候,完整 OCR 编辑器或文档级 OCR 流程可能更对口:
- 你需要把整个 PDF 转换成一份可检索的文档
- 你要一次处理很多页面
- 你需要编辑、批注或重建文件的功能
- 你想在整个文件范围内保留文档结构
但这和「快速从某个可见区域取出文字」并不是同一件事。
这篇文章说的,其实是一个常见又实际的烦恼:文字就在你屏幕上,普通复制却用不了。针对这个具体问题,可视化 OCR 流程往往是更清爽的解法。
如果你还遇到类似的 PDF、截图或文字提取问题,也可以在 RoxyApps 博客 里看看其他实用的 Windows 指南。
常见问题(FAQ)
我明明看得清,为什么复制不了 PDF 里的文字?
因为屏幕上可读的文字,不一定是真实、可选中的文字。这一页可能是扫描件、嵌入的图片,或带复制限制的内容。
怎么判断一个 PDF 是扫描件还是文字版?
试着选中一个词,再用 Ctrl + F 搜索。如果整页像一张图片那样被一起选中,或者搜不到你看得见的词,这个 PDF 多半是扫描件或基于图片的。
受限制的 PDF 和扫描件 PDF 会不会感觉一样?
会。两者都会表现出同一个症状:文字复制不了。区别在于,扫描件 PDF 没有文字层,而受限制的 PDF 可能含有真实文字、却通过权限禁止了复制。
在 Windows 上从扫描件 PDF 提取文字最快的办法是什么?
如果你需要把整份文档转换,走完整 OCR 流程是合适的。如果你只要快速取出某个可见区域,Screenie 这类可视化 OCR 工具通常更快、更简单。
OCR 只能用于 PDF 吗?
不是。只要文字在屏幕上看得见,OCR 也能从截图、扫描图片、图表、应用、网页、演示文稿、甚至视频字幕里提取文字。
为什么我的 PDF 只有一部分能复制文字?
这通常意味着文件是图文混排。有些部分可能是真实文字,另一些则是需要 OCR 的截图、扫描件或嵌入图形。
「OCR PDF」是一种特殊的 PDF 吗?
并不是。人们通常指的是「已经做过 OCR、让基于图片的文字变得可检索或可提取」的 PDF。它描述的是一套流程,而不是另一种 PDF 物种。
如果只要一个段落,有必要转换整个 PDF 吗?
通常没必要。当你真正想要的只是某一段可见文字、某个表格单元格、某条图注,或某块截图区域时,整份文档的转换往往是多余的。
不重建整个文件,能从受限制的 PDF 里提取文字吗?
对一小块可见区域来说,可以。可视化 OCR 流程常常能取到你需要的文字,而不必逼你走一遍完整的文档转换。
参考链接
总结
「Windows 上的 PDF 文字复制不了」这个问题,根源通常不在 Windows,而在文件本身。先花一分钟做个诊断:试着选中一个词、用 Ctrl + F 搜索、放大看看那些字。
如果文字是真实的,自带阅读器就够用了。如果是扫描件,你就需要 OCR。而如果真正的任务只是快速抓取屏幕上看得见的一小段文字,Screenie OCR Text Recognition Tool 这类可视化 OCR 工具,往往比把整个文件转换一遍更省事。
「文字就在屏幕上」和「真正把它取出来」之间的差别,正在于此。