「選不中」的 PDF 難題
文字明明就在頁面上,游標卻怎麼也選不中。你拖著滑鼠劃過一句話,要麼什麼都沒發生,要麼整頁像一張平鋪的圖片一樣被一起選取。多數情況下,問題根本不在 Windows,而在於這個 PDF 是怎麼做出來的。
PDF 並不會自動就是一份「真正的文字文件」。有些 PDF 裡含有可以選取、檢索、複製的真實文字層;有些只是套在 PDF 容器裡的圖片;還有一些含有正常文字,但製作者加了複製限制,不讓你的閱讀器把文字取出來。
這個區別很重要,因為複製文字和用 OCR 擷取文字,根本不是同一套流程。
先說結論: 如果 PDF 裡的文字是真實、可選取的,Edge、Chrome、Adobe Reader 這類內建閱讀器通常就夠用了。如果整頁像一張圖片一樣,就需要 OCR。如果文字看著正常卻仍然複製不了,這個檔案可能加了複製限制。要快速取出看得見的文字,最實用的免費做法是先試試內建的選取複製。而最省事的路徑,是用 Screenie OCR Text Recognition Tool 這類視覺化 OCR 工具——它直接從你螢幕上已經看到的畫面裡把文字抓出來。
📊 比較:擷取文字的幾種方式
| 方式 | 適用於普通文字版 PDF? | 適用於掃描檔 PDF? | 適合情境 | 主要取捨 |
|---|---|---|---|---|
| Edge / Chrome / Adobe Reader | ✅ 可以 | ❌ 不行 | 從真實文字版 PDF 裡快速複製 | 沒有文字層、或複製被限制時就無能為力 |
| 線上 OCR/PDF 轉換工具 | ✅ 可以 | ✅ 可以 | 整份文件的轉換 | 要先上傳、流程繁瑣,為了一段文字往往太費事 |
| 完整 OCR 編輯器或 PDF 套件 | ✅ 可以 | ✅ 可以 | 重度編輯或整份文件的處理 | 設定和複雜度,比很多人實際需要的高 |
| Screenie(視覺化 OCR) | ✅ 可以 | ✅ 可以 | 快速抓取螢幕上看得見的文字 | 最適合只要某個區域、而非重建整份 PDF 的情況 |
說句實在話,其實很簡單。內建閱讀器值得肯定:當檔案本身就含有真實文字時,它是最佳選擇。線上 OCR 工具在你確實需要處理整份文件時很方便。完整 OCR 編輯器在更大的工作流裡很強大。但當你的真實處境是「我現在只要這一塊看得見的文字」時,視覺化 OCR 工具往往是最聰明的折衷。
到底是什麼讓你複製不了文字
如果你在 Windows 上沒法從 PDF 裡複製文字,通常是下面三種原因之一。
1. 這個 PDF 其實是掃描檔
掃描檔 PDF 往往只是一個 PDF 檔案裡裝著的一張圖片。頁面看起來清清楚楚,可你的電腦看到的並不是文字,而是像素。
這就是為什麼拖動游標時,整頁會被當作一大塊一起選取,而不是一個詞一個詞地選。這是檔案沒有真實文字層最明顯的訊號之一。
什麼是掃描檔 PDF? 掃描檔 PDF 是指每一頁都以圖片、而非可選取文字的形式儲存的文件。它看上去可能和普通 PDF 一樣,但複製會失敗,因為頁面影像底下根本沒有真實的字元。
2. 這個 PDF 加了複製限制
PDF 檔案可以包含權限設定,限制閱讀器允許你做什麼。一種常見的限制,就是禁止複製文字。
這種情況下,文字可能是真實、可讀的,但軟體遵守檔案的規則,拒絕把它複製出來。
為什麼一個 PDF 能正常開啟,卻不讓你複製文字? 因為「開啟 PDF」和「從 PDF 複製」是兩種不同的權限。一個檔案可以在螢幕上正常閱讀,同時在閱讀器內部仍然禁止複製內容。
3. 這一頁是圖文混排
有些 PDF 內容很雜。同一頁裡,某一部分是真實可選取的文字,另一部分卻嵌著截圖、示意圖、簽名或掃描插頁。這就造成了讓人困惑的現象:一個段落能正常複製,旁邊的表格卻不行。
這在合約、報告、表單、說明書,以及匯出的商務文件裡很常見。
為什麼看得見的文字不一定能選取 螢幕上看著可讀的文字,實際上可能是圖片、截圖、圖表、影片畫面或應用程式畫布的一部分。只要沒有文字層,普通的複製貼上就用不了——哪怕這些字在你看來清清楚楚。
怎麼判斷 PDF 裡有沒有真實文字
在你動手轉換檔案、或安裝笨重的軟體之前,先做一個快速診斷。
試著選取一個詞
在 Edge、Chrome 或 Adobe Reader 裡開啟 PDF,試著選取頁面中間的某一個詞。
- 如果你能選取單個的詞或行,這個 PDF 多半含有真實文字。
- 如果整頁像一個矩形或一張圖片那樣被一起反白,這一頁多半是掃描檔。
- 如果有些部分能選取、有些不能,這個 PDF 很可能是圖文混排。
放大看看那些字
這是一條很多文章會跳過、但很實用的內行線索。
如果你放大後,發現字母略微發虛、不齊整、或帶點照片感,這一頁可能是基於圖片的。真實文字在放大時通常依然清晰,因為它是作為字元被算繪出來的,而不是像圖片那樣被拉伸。
試試搜尋
按 Ctrl + F,搜尋一個你在頁面上清楚看到的詞。
- 如果搜得到,多半是有文字層的。
- 如果那個詞明明就在那兒、卻搜不到,這一頁可能是掃描檔或純圖片內容。
話說回來,一個檔案也可能既有文字層、又透過權限禁止了複製。所以「能搜尋的 PDF」並不自動等於「能複製的 PDF」。
大家通常先試什麼——以及為什麼常常沒用
多數人會先做那件最順手的事:在 Edge、Chrome 或 Adobe Reader 裡開啟檔案,試著拖動選取文字。一旦失敗,就以為是 Windows 出了問題,或者 PDF 閱讀器太差。
接著,冤枉路就開始了。
- 換一個 PDF 應用程式,結果還是一樣。
- 把文件上傳到某個隨便搜到的線上轉換工具。
- 明明只要一段,卻把整個 PDF 都轉換了。
- 截個圖,然後手動把文字重新打一遍。
- 把時間浪費在解決錯誤的問題上——因為癥結是檔案本身,而不是閱讀器。
之所以會陷入這種套路,是因為不同的原因表現出同樣的症狀。一個受限制的 PDF 和一個掃描檔 PDF,都會讓人覺得「我複製不了這段文字」,但背後的原因完全不同。
這是一個重要的區別:
- 掃描檔 PDF: 根本沒有可複製的真實文字。
- 受限制的 PDF: 可能有真實文字,但閱讀器不允許複製。
- PDF 裡的圖片: 只有那一部分需要 OCR,未必是整份文件。
值得先試的內建與免費選項
在跳到 OCR 之前,先走簡單路線是合理的。
Edge、Chrome 或 Adobe Reader
如果 PDF 含有真實文字、又沒有複製限制擋著你,這些內建或常見的閱讀器通常就夠了。選取文字、複製,然後接著幹活。
這是阻力最小的路線,能用時它就是對的那個。
能搜尋卻仍複製失敗
如果文件能搜尋、複製卻失敗,那這個檔案可能加了限制。這種情況下,換閱讀器也未必有用,因為限制是檔案規則的一部分。
用完整轉換工具做 OCR
如果 PDF 是掃描檔,而你需要把整個檔案變成可檢索的文字,走一遍完整的 OCR 流程是說得通的。當你處理的是長篇報告、多個頁面或封存文件時,這條路更對口。
問題在於,對日常的實際需求來說,這個辦法往往太重了。如果你要的不過是一個地址、一句話、一個段落,或是 PDF 裡某張截圖上的一塊文字,把整個檔案都轉換一遍就顯得很笨拙。
什麼時候真的需要 OCR
OCR 是 Optical Character Recognition(光學字元辨識)的縮寫。它從圖片裡讀出看得見的字母,再把它們變成你能複製的真實文字。
什麼是 OCR? OCR 是從圖片、掃描檔、截圖或其他視覺來源中辨識文字,並把它轉換成可編輯、可選取文字的過程。
當沒有可直接複製的可用文字層時,你就需要 OCR。
這包括一些常見情況:
- 掃描的合約或信件
- 拍照後轉成的 PDF
- 以圖片形式存在 PDF 裡的表格或示意圖
- 畫質不佳的辦公掃描檔
- 以圖片形式匯出到 PDF 裡的簡報投影片
- 出現在影片畫面、截圖或應用程式視窗裡的文字
很多人就是在這一步浪費了時間,試圖去「解鎖」一個根本沒被鎖的東西。其實那裡壓根就沒有可複製的文字。
聰明的折衷:用視覺化 OCR,而非整份轉換
如果你的目標只是抓取螢幕上已經看得見的文字,對整份文件做 OCR 往往是殺雞用牛刀。
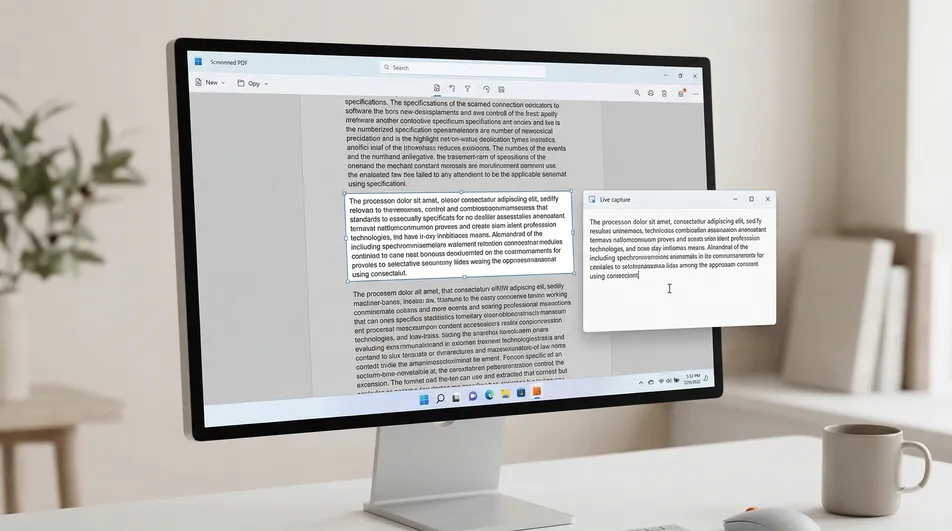
這正是 Screenie OCR Text Recognition Tool 的用武之地。它不去重建整個 PDF,而是從你在螢幕上框選的可見區域裡擷取文字。
所以在這些時候,它格外實用:
- 你只要幾行,而不是整個檔案
- PDF 裡只有一頁掃描檔,或一張嵌入的截圖
- 你要從圖表、圖片或示意圖裡複製文字
- 文字出現在網頁、應用程式、簡報或影片字幕裡
- 你不想為了一小段文字,去走一遍完整的 PDF 轉換流程
權衡下來,決定其實很清楚:
- 用內建複製——當 PDF 含有真實、可選取的文字。
- 用完整 OCR 或轉換——當你需要對整份文件做處理。
- 用視覺化 OCR——當真正的任務只是快速抓取看得見的文字。
這就是為什麼 Screenie 在這裡是個實用的推薦。它比完整 OCR 編輯器更簡單,比為一段文字轉換整個檔案更快,也更契合「我現在就要這段文字」的場景。
一分鐘內從 PDF 裡擷取文字的方法
下面這些步驟,在「文字看得見卻選不中」時尤其好用。
-
用你常用的閱讀器開啟 PDF。 Edge、Chrome、Adobe Reader 都行。檔案不用挪到任何別的地方。
-
找到你需要的確切區域。 捲動到包含目標文字的那個段落、圖說、表格或圖片區域。
-
先試試內建複製能不能用。 選取一個詞試試。如果普通反白能用,就直接複製,跳過 OCR。
-
選取失敗時用 Screenie。 啟動 Screenie OCR Text Recognition Tool,啟用擷取區域。
-
框住看得見的文字。 只選你真正需要的那部分。這通常能提速,也讓結果更乾淨。
-
把擷取出的文字貼到需要的地方。 擷取完成後,貼到 Word、郵件、筆記、Slack,或你正在用的任何地方。
當真正的任務很小的時候,這種視覺化的辦法,往往比匯出、轉換、或對整個檔案做 OCR 更快。
讓人困惑的高頻特殊情況
看著很正常的掃描合約
掃描的合約可能看上去就像一份普通的數位 PDF,因為螢幕上的字夠清晰。但只要拖動游標時整頁像一張圖片那樣被選取,就需要 OCR。
一部分能選取的 PDF
這是檔案圖文混排的有力線索。內文可能是真實文字,而簽名、截圖、側欄或示意圖卻是基於圖片的。這種情況下,能用的地方就用普通複製,只在不能用的地方用 OCR。
圖表、表格、截圖裡的文字
哪怕在一份正常的 PDF 裡,嵌入圖形內部的文字往往也選不中。標準的 PDF 複製對段落或許有用,對圖表裡的標籤卻會失敗。對那塊區域,視覺化 OCR 工具通常更合適。
低解析度掃描檔
OCR 不是魔法。如果原件發虛、歪斜、壓縮得厲害或對比度很低,辨識準確率會下降。這不僅關乎工具,也關乎原件品質。
多欄版面
當一頁裡有窄欄、側註或互相重疊的視覺元素時,有些 OCR 流程會處理得很亂。與其對整頁做 OCR,不如框選更小的區域,往往能得到更乾淨的結果。
最後這一點,比多數人意識到的更重要。把整個 PDF 都轉換,並不總是更聰明的做法。當版面很複雜時,只抓取你在意的那一小塊可見內容,反而能帶來更好的實際效果。
疑難排解:如果擷取結果仍然很亂
如果你拿到的文字很差或不完整,問題未必只出在檔案上。試試這些檢查。
字母看著發虛
放大看看。如果掃描本身就模糊,OCR 準確率通常會受影響。換一個更清晰的縮放等級,或框得更緊一點,都會有幫助。
這一頁是圖文混排
如果只有某個框或某個段落要緊,就別擷取整頁。抓取更小的區域,往往能減少混亂。
版面有分欄或側註
一次抓一欄、或一節,而不是想一口氣把整頁都 OCR 掉。
PDF 像是被鎖住了
如果你能搜尋文字、卻複製不了,這個檔案可能是受限制、而非掃描檔。這種情況下,對小段擷取來說,視覺化 OCR 仍然是更快的變通辦法。
你只要一句短引文
別浪費時間去轉換整份文件。這正是「針對性視覺化 OCR 比完整 PDF 流程更合適」的典型場景。
什麼時候完整 OCR 工具更合適
說句公道話:Screenie 並不是每一個 PDF 問題的答案。
在這些時候,完整 OCR 編輯器或文件級 OCR 流程可能更對口:
- 你需要把整個 PDF 轉換成一份可檢索的文件
- 你要一次處理很多頁面
- 你需要編輯、註解或重建檔案的功能
- 你想在整個檔案範圍內保留文件結構
但這和「快速從某個可見區域取出文字」並不是同一件事。
這篇文章說的,其實是一個常見又實際的煩惱:文字就在你螢幕上,普通複製卻用不了。針對這個具體問題,視覺化 OCR 流程往往是更清爽的解法。
如果你還遇到類似的 PDF、截圖或文字擷取問題,也可以在 RoxyApps 部落格 裡看看其他實用的 Windows 指南。
常見問題(FAQ)
我明明看得清,為什麼複製不了 PDF 裡的文字?
因為螢幕上可讀的文字,不一定是真實、可選取的文字。這一頁可能是掃描檔、嵌入的圖片,或帶複製限制的內容。
怎麼判斷一個 PDF 是掃描檔還是文字版?
試著選取一個詞,再用 Ctrl + F 搜尋。如果整頁像一張圖片那樣被一起選取,或者搜不到你看得見的詞,這個 PDF 多半是掃描檔或基於圖片的。
受限制的 PDF 和掃描檔 PDF 會不會感覺一樣?
會。兩者都會表現出同一個症狀:文字複製不了。區別在於,掃描檔 PDF 沒有文字層,而受限制的 PDF 可能含有真實文字、卻透過權限禁止了複製。
在 Windows 上從掃描檔 PDF 擷取文字最快的辦法是什麼?
如果你需要把整份文件轉換,走完整 OCR 流程是合適的。如果你只要快速取出某個可見區域,Screenie 這類視覺化 OCR 工具通常更快、更簡單。
OCR 只能用於 PDF 嗎?
不是。只要文字在螢幕上看得見,OCR 也能從截圖、掃描圖片、圖表、應用程式、網頁、簡報、甚至影片字幕裡擷取文字。
為什麼我的 PDF 只有一部分能複製文字?
這通常意味著檔案是圖文混排。有些部分可能是真實文字,另一些則是需要 OCR 的截圖、掃描檔或嵌入圖形。
「OCR PDF」是一種特殊的 PDF 嗎?
並不是。人們通常指的是「已經做過 OCR、讓基於圖片的文字變得可檢索或可擷取」的 PDF。它描述的是一套流程,而不是另一種 PDF 物種。
如果只要一個段落,有必要轉換整個 PDF 嗎?
通常沒必要。當你真正想要的只是某一段可見文字、某個表格儲存格、某條圖說,或某塊截圖區域時,整份文件的轉換往往是多餘的。
不重建整個檔案,能從受限制的 PDF 裡擷取文字嗎?
對一小塊可見區域來說,可以。視覺化 OCR 流程常常能取到你需要的文字,而不必逼你走一遍完整的文件轉換。
參考連結
總結
「Windows 上的 PDF 文字複製不了」這個問題,根源通常不在 Windows,而在檔案本身。先花一分鐘做個診斷:試著選取一個詞、用 Ctrl + F 搜尋、放大看看那些字。
如果文字是真實的,內建閱讀器就夠用了。如果是掃描檔,你就需要 OCR。而如果真正的任務只是快速抓取螢幕上看得見的一小段文字,Screenie OCR Text Recognition Tool 這類視覺化 OCR 工具,往往比把整個檔案轉換一遍更省事。
「文字就在螢幕上」和「真正把它取出來」之間的差別,正在於此。