「選択できない」PDFの問題
文字はちゃんとページに表示されているのに、カーソルでなぞっても反転(ハイライト)しない。一文をドラッグしても何も起きないか、ページ全体が1枚の平らな画像のようにまとめて選択される。多くの場合、原因はWindowsそのものではありません。そのPDFの作られ方にあります。
PDFは、自動的に「本物のテキスト文書」になるわけではありません。選択・検索・コピーができる本物のテキスト層を持つPDFもあれば、PDFという容器に画像を包んだだけのものもあります。さらに、普通のテキストは入っているのに、作成者がコピー制限を加えていて、ビューアーが文字の取得を許さないものもあります。
この違いが重要なのは、文字をコピーすることと、OCRで文字を抽出することは、まったく別の作業だからです。
結論から先に: PDFの文字が本物で選択できる状態なら、Edge・Chrome・Adobe Reader といった標準ビューアーでたいてい事足ります。ページが1枚の画像のように振る舞うなら、OCRが必要です。文字は普通に見えるのにコピーだけ拒まれるなら、そのファイルにはコピー制限がかかっているのかもしれません。見えている文字だけをサッと取り出したいなら、まずは標準の選択を試すのが一番手軽な無料の方法です。そして最もスムーズなのは、Screenie OCR Text Recognition Tool のような画面OCRツールで、いま画面に見えている範囲から直接テキストを取り込む方法です。
📊 比較:文字を取り出すおすすめの方法
| 方法 | 通常のテキストPDF | スキャンPDF | 向いている用途 | 主なトレードオフ |
|---|---|---|---|---|
| Edge / Chrome / Adobe Reader | 対応 | 非対応 | 本物のテキストPDFからの素早いコピー | テキスト層がない、またはコピーが制限されていると使えない |
| オンラインOCR/PDF変換ツール | 対応 | 対応 | 文書まるごとの変換 | アップロードの手間。一段落のためには大げさになりがち |
| 本格的なOCRエディター/PDF統合ソフト | 対応 | 対応 | 本格的な編集や文書まるごとの処理 | 多くの人にとっては準備も複雑さも過剰 |
| Screenie(画面OCR) | 対応 | 対応 | 画面に見えている文字を素早く取り込む | PDFまるごとの再構築ではなく、特定の範囲が欲しいときに最適 |
率直に整理すると、こうなります。標準ビューアーは正当に評価されるべきで、ファイルにすでに本物のテキストが入っているなら最良の選択肢です。オンラインOCRツールは、本当に文書全体を処理したいときには便利です。本格的なOCRエディターは、大きなワークフローでは強力です。しかし、実際の状況が「いま、この見えている文字のかたまりだけが欲しい」というものなら、画面OCRツールが最も賢い中間地点になることがよくあります。
文字のコピーを実際に妨げているもの
WindowsでPDFの文字をコピーできない場合、原因はたいてい次の3つのどれかです。
1. PDFが実はスキャン画像
スキャンPDFは、PDFファイルの中に画像が入っているだけ、というケースがよくあります。ページは一見すると問題なく読めますが、コンピューターは「文字」を見ているのではありません。「ピクセル」を見ているのです。
だからこそ、カーソルでドラッグすると、1単語ずつではなくページ全体が1つの大きなかたまりとして選択されてしまうのです。これは、そのファイルに本物のテキスト層がないことを示す、最もわかりやすいサインの1つです。
スキャンPDFとは: 各ページが、選択可能なテキストではなく画像として保存されている文書のことです。見た目は普通のPDFと変わりませんが、ページ画像の下に本物の文字が存在しないため、コピーが失敗します。
2. PDFにコピー制限がかかっている
PDFファイルには、ビューアーが許可する操作を制限する権限(セキュリティ設定)を含めることができます。よくある制限の1つが、文字コピーの無効化です。
この場合、文字自体は本物で読めるのに、ソフトがファイルのルールに従ってコピーを拒否します。
なぜPDFは普通に開けるのに文字をコピーできないことがあるのか: PDFを「開く」ことと、PDFから「コピーする」ことは、別々の権限だからです。画面上では読めても、ビューアー内での内容コピーはブロックされている、ということがあり得ます。
3. ページに複数の種類の内容が混在している
雑多な作りのPDFもあります。1つのページの中で、ある部分は本物の選択可能なテキストなのに、別の部分にはスクリーンショット・図・署名・スキャンの差し込みが埋め込まれている、ということがあります。すると、ある段落は普通にコピーできるのに、隣の表はコピーできない、という紛らわしい挙動になります。
これは契約書・報告書・フォーム・マニュアル・業務システムから書き出した文書などでよく見られます。
見えている文字が、いつも選択できるとは限らない理由: 画面で読めているように見える文字が、実は画像・スクリーンショット・グラフ・動画のフレーム・アプリの描画領域の一部であることがあります。テキスト層がなければ、たとえ文字がはっきり見えていても、通常のコピー&ペーストは効きません。
そのPDFに本物の文字が入っているかを見分ける方法
ファイルを変換し始めたり、重いソフトをインストールしたりする前に、まず手早く1つ診断しておきましょう。
1単語だけ反転させてみる
PDFを Edge・Chrome・Adobe Reader で開き、ページの真ん中あたりにある1単語だけを反転させてみます。
- 単語や行を個別に選択できるなら、そのPDFはおそらく本物の文字を含んでいます。
- ページ全体が1つの四角や画像のように反転するなら、そのページはおそらくスキャンです。
- 一部は選択でき、別の部分は選択できないなら、そのPDFはテキストと画像が混在している可能性が高いです。
拡大して文字をよく見る
これは、多くの記事が飛ばしている、知っておくと便利な手がかりです。
拡大したときに文字が少しぼやけて見えたり、にじんでいたり、写真のように見えたりするなら、そのページは画像ベースかもしれません。本物の文字は、写真のように引き伸ばされるのではなく文字として描画されるため、拡大してもくっきりしたままなのが普通です。
検索を試す
Ctrl + F を押して、ページにはっきり見えている単語を検索してみます。
- 検索でヒットするなら、おそらくテキスト層があります。
- 単語がそこに見えているのに検索で何も見つからないなら、そのページはスキャンか画像のみの内容かもしれません。
ただし、テキスト層があってもコピーは権限でブロックされていることがあります。つまり、「検索できるPDF」が、そのまま「コピーできるPDF」になるとは限りません。
多くの人が最初に試すこと、そしてなぜ失敗しがちなのか
たいていの人は、まず当たり前のことをします。ファイルを Edge・Chrome・Adobe Reader で開き、文字をドラッグして選択しようとします。それが失敗すると、「Windowsが壊れた」「PDFビューアーがダメだ」と思い込んでしまいます。
そこから、遠回りが始まります。
- 別のPDFアプリで試すが、同じ結果になる。
- 適当なオンライン変換サイトに文書をアップロードする。
- 一段落しか必要ないのに、PDF全体を変換する。
- スクリーンショットを撮って、手で文字を打ち直す。
- 問題はファイル自体にあるのに、ビューアーのせいだと勘違いして、見当違いの対処に時間を浪費する。
このパターンが起きるのは、原因が違っても症状が同じだからです。保護されたPDFもスキャンPDFも、どちらも「この文字がコピーできない」と感じさせますが、その理由はまったく異なります。
これは重要な区別です。
- スキャンPDF: そもそもコピーできる本物の文字が存在しない。
- 保護されたPDF: 本物の文字はあるかもしれないが、ビューアーがコピーを許可していない。
- PDF内の画像: ページのその部分だけにOCRが必要で、文書全体に必要とは限らない。
まず試す価値のある標準・無料の選択肢
OCRに飛びつく前に、シンプルな方法を試すのが理にかなっています。
Edge・Chrome・Adobe Reader
PDFに本物の文字が入っていて、コピー制限にも阻まれていないなら、これらの標準ビューアーやよく使われるビューアーでたいてい事足ります。文字を反転させ、コピーして、それで完了です。
これは最も手間の少ない方法で、うまくいくならこれが正解です。
検索はできるのにコピーが失敗する場合
文書を検索できるのにコピーが失敗するなら、そのファイルは制限されている可能性があります。その場合、制限はファイルのルールの一部なので、ビューアーを変えても解決しないことがあります。
本格的な変換ツールでのOCR
PDFがスキャンで、ファイル全体を検索可能なテキストに変えたいなら、本格的なOCRワークフローが理にかなうこともあります。長い報告書、複数ページ、保存用の文書を扱うときに、特に当てはまります。
問題は、この方法が現実のふつうの用途には大げさすぎることがよくある点です。住所1つ、引用1つ、段落1つ、あるいはPDFに埋め込まれたスクリーンショットの一部分だけが欲しいだけなら、ファイル全体を変換するのは不格好です。
OCRが本当に必要になるとき
OCRは Optical Character Recognition(光学文字認識)の略です。画像の中に見えている文字を読み取り、コピーできる本物のテキストに変換します。
OCRとは: 画像・スキャン・スクリーンショットなど、視覚的なソースから文字を認識し、編集・選択できるテキストに変換する処理のことです。
直接コピーできる使えるテキスト層がないとき、OCRが必要になります。
たとえば次のようなよくあるケースです。
- スキャンした契約書や手紙
- 写真をPDF化したもの
- PDF内に画像として保存された表や図
- 画質の低いオフィスのスキャン
- 画像としてPDFに書き出されたプレゼン資料のスライド
- 動画のフレーム・スクリーンショット・アプリ画面に見えている文字
ここで多くの人が、そもそもロックされてもいないものを「解除」しようとして時間を浪費します。コピーすべき文字が、最初から1文字も存在しないのです。
賢い中間地点:全体変換ではなく画面OCR
目的が「いま画面に見えている文字だけを取り込むこと」なら、文書まるごとのOCRはたいてい過剰です。
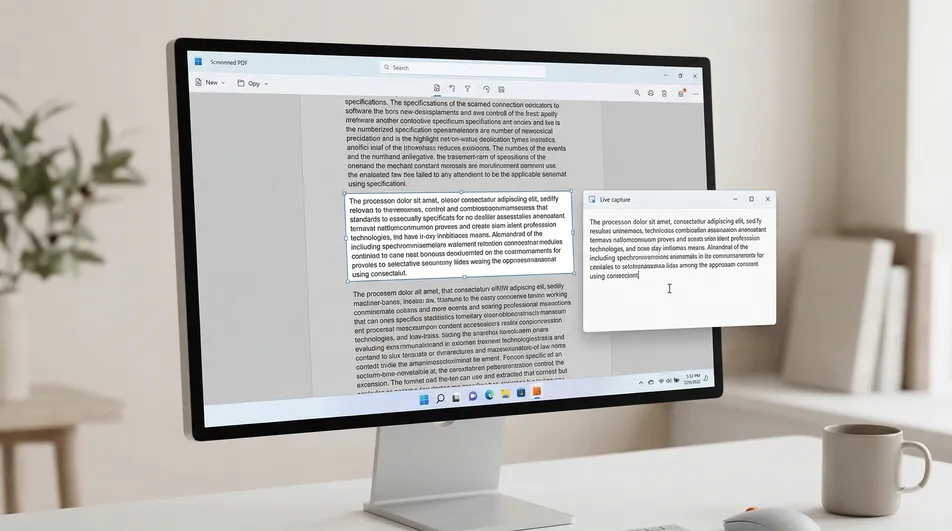
そこにうまくはまるのが Screenie OCR Text Recognition Tool です。PDF全体を作り直すのではなく、画面上で選んだ見えている範囲から文字を抽出します。
そのため、特に次のような場面で実用的です。
- ファイル全体ではなく、数行だけ必要なとき
- PDFにスキャンページが1枚、あるいは埋め込みスクリーンショットが1つだけあるとき
- グラフ・画像・図から文字をコピーしたいとき
- 文字がWebサイト・アプリ・プレゼン・動画の字幕に見えているとき
- たった一節を取り出すために、PDFの変換作業をまるごと通したくないとき
こうしたトレードオフを踏まえると、判断はシンプルになります。
- PDFに本物の選択可能なテキストが入っているなら、標準のコピーを使う。
- 文書全体の処理が必要なら、本格的なOCRや変換を使う。
- 本当の用事が「見えている文字を素早く取り込む」ことなら、画面OCRを使う。
だからこそ、この記事ではScreenieが実用的な推奨になります。本格的なOCRエディターよりシンプルで、一段落のためにファイル全体を変換するより速く、「この文字がいますぐ欲しい」という状況に向いているのです。
手順:WindowsでPDFから1分以内に文字を取り出す
次の手順は、文字が見えているのに選択できないときに、特にうまく機能します。
-
いつものビューアーでPDFを開きます。 Edge・Chrome・Adobe Reader、どれでも構いません。ファイルをどこかへ移す必要はありません。
-
必要な範囲を正確に探します。 目的の文字が含まれる段落・キャプション・表・画像の部分までスクロールします。
-
まず標準のコピーが効くか確認します。 1単語だけ選択してみましょう。通常の反転ができるなら、そのまま直接コピーして、OCRは省略します。
-
選択できないときはScreenieを使います。 Screenie OCR Text Recognition Tool を起動し、取り込み範囲を有効にします。
-
見えている文字を囲むように範囲を指定します。 本当に必要な部分だけを選びましょう。たいてい速くなり、結果もきれいになります。
-
抽出した文字を必要な場所に貼り付けます。 取り込みが終わったら、Word・メール・メモ・チャットなど、作業している場所に貼り付けます。
この視覚的な方法は、用事が小さいときには、ファイル全体を書き出したり変換したりOCRにかけたりするよりも、しばしば速く済みます。
多くの人を混乱させる、覚えておきたい特殊なケース
普通に見えるスキャン契約書
スキャンした契約書は、画面上では文字が十分くっきり見えるため、普通のデジタルPDFのように見えることがあります。しかし、カーソルでドラッグしてページが1枚の画像のように選択されるなら、OCRが必要です。
一部だけ選択できるPDF
これは、そのファイルに複数の種類の内容が混在していることを示す強い手がかりです。本文は本物の文字でも、署名・スクリーンショット・サイドバー・図は画像ベースかもしれません。その場合は、効くところでは通常のコピーを使い、効かないところだけOCRを使います。
グラフ・表・スクリーンショットの中の文字
普通のPDFでも、埋め込まれた図の中の文字は選択できないことがよくあります。標準のコピーは段落には効いても、グラフ内のラベルには効かない、ということがあります。その範囲には、画面OCRツールのほうがたいてい向いています。
解像度の低いスキャン
OCRは魔法ではありません。元の画像がぼやけていたり、傾いていたり、強く圧縮されていたり、コントラストが低かったりすると、認識精度は下がることがあります。これはツールの問題だけでなく、元の品質の問題でもあります。
段組みレイアウト
ページに狭い段組み・傍注・重なり合う視覚要素があると、OCRの結果が乱れることがあります。ページ全体ではなく、より小さな範囲を選ぶほうが、きれいな結果になりがちです。
この最後の点は、多くの人が思っている以上に重要です。PDF全体を変換するのが、いつも賢いとは限りません。レイアウトが複雑なときは、気になる見えている部分だけを取り込むほうが、実用上よい結果になることがあります。
トラブルシューティング:抽出結果がまだ乱れる場合
文字がうまく取れない、欠ける、というときは、ファイルだけが問題とは限りません。次の点を確認してみてください。
文字がぼやけて見える
拡大してみましょう。スキャンがぼやけていると、たいていOCRの精度は落ちます。きれいに見える拡大率にする、取り込み範囲を絞る、といった工夫が役立ちます。
ページに複数の内容が混在している
1つの枠や段落だけが必要なら、ページ全体は取り込まないでください。小さな範囲を取り出すほうが、混乱が減ることがよくあります。
段組みや傍注がある
ページ全体を一度にOCRしようとせず、1段ずつ、あるいは1セクションずつ取り込みましょう。
PDFが保護されているように見える
文字を検索できるのにコピーできないなら、そのファイルはスキャンではなく制限されているのかもしれません。その場合でも、小さな抽出作業なら、画面OCRのほうが速い回避策になります。
短い引用が1つ欲しいだけのとき
文書全体を変換して時間を無駄にしないでください。まさにこういう状況こそ、PDFの一連の作業より、狙いを絞った画面OCRのほうが理にかなっています。
本格的なOCRツールのほうが向いているとき
正直に書いておくと、ScreenieはすべてのPDFの問題に対する答えではありません。
次のようなときは、本格的なOCRエディターや文書OCRのワークフローのほうが向いています。
- PDF全体を検索可能な文書に変換したいとき
- 一度に多くのページを処理したいとき
- 編集・注釈・ファイルの再構築機能が必要なとき
- 文書全体で構造を保持したいとき
ただし、これは「見えている範囲1つから素早く文字を取り出す」という作業とは別物です。
この記事が扱っているのは、よくある実用的な悩みです——文字は画面に出ているのに、通常のコピーが効かない、という問題です。まさにその問題に対しては、画面OCRのワークフローのほうがすっきりした解決策になることがよくあります。
似たようなPDF・スクリーンショット・文字抽出の悩みがあるなら、RoxyAppsブログ の他の実用ガイドもあわせてご覧ください。
よくある質問(FAQ)
はっきり読めるのに、PDFの文字をコピーできないのはなぜ?
画面で読める文字が、いつも本物の選択可能なテキストとは限らないからです。そのページはスキャンや埋め込み画像かもしれませんし、コピー制限のかかった内容かもしれません。
PDFがスキャンかテキストベースかは、どう見分けますか?
1単語だけ反転させてみるか、Ctrl + F で検索してみてください。ページ全体が1枚の画像のように振る舞う、または見えている単語が検索で見つからないなら、そのPDFはスキャンか画像ベースの可能性が高いです。
保護されたPDFとスキャンPDFは、同じように感じられますか?
はい。どちらも「文字をコピーできない」という同じ症状になり得ます。違いは、スキャンPDFにはテキスト層がないのに対し、保護されたPDFには本物の文字があっても権限でコピーがブロックされている、という点です。
WindowsでスキャンPDFから文字を取り出す一番速い方法は?
文書全体を変換したいなら、本格的なOCRワークフローが適しているかもしれません。見えている範囲だけを素早く取りたいなら、Screenieのような画面OCRツールのほうがたいてい速くてシンプルです。
OCRはPDFだけにしか使えませんか?
いいえ。OCRは、文字が画面に見えてさえいれば、スクリーンショット・スキャン画像・グラフ・アプリ・Webサイト・プレゼン、さらには動画の字幕からも文字を抽出できます。
PDFの一部分だけコピーできるのはなぜ?
たいていは、そのファイルに複数の種類の内容が混在していることを意味します。あるセクションは本物の文字でも、別の部分はスクリーンショット・スキャン・埋め込み図で、OCRが必要なのです。
「OCR済みPDF」は特別な種類のPDFですか?
そういうわけではありません。一般には、OCRをかけて画像ベースの文字を検索・抽出できるようにしたPDFを指します。別種のPDFというより、処理の状態を表す言い方です。
一段落しか必要ないのに、PDF全体を変換する必要がありますか?
たいてい不要です。本当の目的が、見えている段落・表のセル・キャプション・スクリーンショットの範囲を1つ取り込むことなら、文書全体の変換は多くの場合いりません。
ファイル全体を作り直さずに、保護されたPDFから文字を取り出せますか?
見えている小さな範囲なら、可能なことが多いです。画面OCRのワークフローなら、文書全体の変換を強いられることなく、必要な文字を取り出せることがよくあります。
参考リンク
- Adobe Reader ヘルプ:PDF からコンテンツをコピーする
- Adobe Acrobat ヘルプ:文書をスキャンして PDF に変換し、テキストを認識する
- Microsoftサポート:Windows でテキスト認識(OCR)を使う
まとめ
PDFの文字がコピーできないときは、まず「本当にコピーできる文字データが入っているのか」を確認してください。それだけで、見当違いの対処に費やす時間の多くを省けます。
文字が画像になっているなら、OCRが必要です。一方、見た目は普通の文字なのにコピーだけ拒まれるなら、それはスキャンではなくコピー制限かもしれません。そして、本当の用事が「見えている範囲を1つだけ素早く取り込むこと」なら、文書全体を変換するより、Screenie OCR Text Recognition Tool で画面範囲を選び、抽出した文字を貼り付ける方法が、いちばん実用的です。
症状は同じでも原因は違う——この一点を押さえておくだけで、選ぶべき方法がはっきり見えてきます。