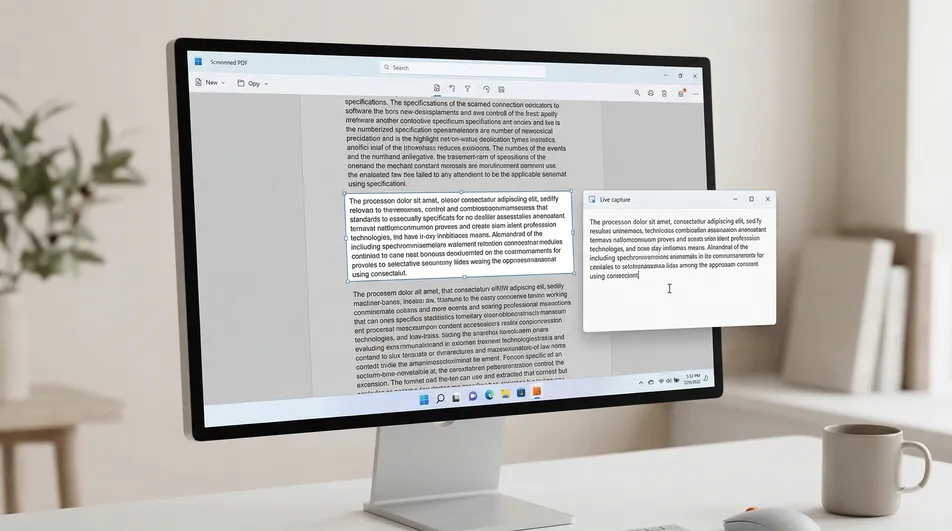
O problema do PDF “não selecionável”
As palavras estão ali, na página, mas o cursor não destaca nada. Você arrasta sobre uma frase e ou nada acontece, ou a página inteira é selecionada como se fosse uma única imagem chapada. Na maioria dos casos, o problema não é o Windows. É a forma como o PDF foi criado.
Um PDF não é automaticamente um documento de texto de verdade. Alguns PDFs contêm uma camada de texto real que você consegue selecionar, pesquisar e copiar. Outros são apenas imagens embrulhadas em um arquivo PDF. E alguns contêm texto normal, mas o criador adicionou restrições de cópia que impedem o seu leitor de deixar você pegá-lo.
Essa distinção importa porque copiar texto e extrair texto com OCR não são o mesmo fluxo de trabalho.
Resposta rápida: se o texto de um PDF é real e selecionável, visualizadores integrados como Edge, Chrome ou Adobe Reader costumam ser suficientes. Se a página se comporta como uma única imagem, o OCR é necessário. Se o texto parece normal mas mesmo assim se recusa a copiar, o arquivo pode ter restrições de cópia. Para extrair rapidamente só o texto visível, o caminho grátis mais prático é tentar primeiro a seleção integrada. O caminho mais simplificado é usar uma ferramenta de OCR visual como o Screenie OCR Text Recognition Tool, que captura o texto diretamente do que você já consegue ver na tela.
📊 Comparação: melhores formas de extrair texto
| Método | Funciona com PDFs de texto normal? | Funciona com PDFs digitalizados? | Ideal para | Principal contrapartida |
|---|---|---|---|---|
| Edge / Chrome / Adobe Reader | ✅ Sim | ❌ Não | Copiar rápido de PDFs com texto real | Falha quando não há camada de texto ou a cópia está restrita |
| OCR online / conversores de PDF | ✅ Sim | ✅ Sim | Conversão do documento inteiro | Etapa de upload, atrito extra, muitas vezes trabalho demais para um parágrafo |
| Editores de OCR completos ou suítes de PDF | ✅ Sim | ✅ Sim | Edição pesada ou fluxos com o documento inteiro | Mais configuração e complexidade do que muitos usuários precisam |
| Screenie (OCR visual) | ✅ Sim | ✅ Sim | Pegar rapidamente o texto visível na tela | Melhor quando você precisa de uma região específica, não de reconstruir o PDF inteiro |
A versão honesta é simples. Os leitores integrados merecem crédito: eles são a melhor opção quando o arquivo já contém texto real. As ferramentas de OCR online podem ser convenientes quando você realmente precisa processar um documento inteiro. Os editores de OCR completos podem ser poderosos para fluxos maiores. Mas quando a sua situação real é “só preciso deste bloco de texto visível agora”, uma ferramenta de OCR visual costuma ser o meio-termo mais inteligente.
O que realmente impede você de copiar o texto
Se você não consegue copiar texto de um PDF no Windows, normalmente é por uma destas três coisas.
1. O PDF é, na verdade, uma digitalização
Um PDF digitalizado é, muitas vezes, apenas uma imagem dentro de um arquivo PDF. A página pode parecer perfeitamente legível, mas o seu computador não está vendo palavras. Ele está vendo pixels.
É por isso que arrastar o cursor pode selecionar a página inteira como um grande bloco, em vez de uma palavra de cada vez. É um dos sinais mais claros de que o arquivo não tem uma camada de texto real.
O que é um PDF digitalizado? Um PDF digitalizado é um documento em que cada página é armazenada como uma imagem, em vez de texto selecionável. Ele pode parecer um PDF normal, mas a cópia falha porque não há caracteres reais por baixo da imagem da página.
2. O PDF tem restrições de cópia
Os arquivos PDF podem incluir permissões que limitam o que o leitor deixa você fazer. Uma restrição comum é desativar a cópia de texto.
Nesse caso, o texto pode ser real e legível, mas o software obedece às regras do arquivo e se recusa a copiá-lo.
Por que um PDF pode abrir normalmente e mesmo assim não deixar você copiar o texto? Porque abrir um PDF e copiar de um PDF são permissões separadas. Um arquivo pode ser legível na tela e ainda assim bloquear a cópia de conteúdo dentro do visualizador.
3. A página tem conteúdo misto
Alguns PDFs são bagunçados. Uma página pode conter texto selecionável real em uma parte e capturas de tela, diagramas, assinaturas ou inserções digitalizadas em outra. Isso gera um comportamento confuso: um parágrafo copia normalmente, mas a tabela ao lado, não.
Isso é comum em contratos, relatórios, formulários, manuais e documentos empresariais exportados.
Por que o texto visível nem sempre é selecionável O texto que parece legível na tela pode, na verdade, fazer parte de uma imagem, captura de tela, gráfico, quadro de vídeo ou tela de aplicativo. Se não há camada de texto, copiar e colar normalmente não vai funcionar, mesmo que as letras pareçam nítidas para você.
Como saber se o PDF contém texto real
Antes de começar a converter arquivos ou instalar softwares pesados, faça um diagnóstico rápido.
Tente destacar uma palavra
Abra o PDF no Edge, no Chrome ou no Adobe Reader e tente destacar uma única palavra no meio da página.
- Se você consegue selecionar palavras ou linhas individuais, o PDF provavelmente contém texto real.
- Se a página inteira é destacada como um único retângulo ou imagem, a página provavelmente é digitalizada.
- Se algumas partes selecionam e outras não, o PDF provavelmente contém conteúdo misto de texto e imagem.
Dê zoom e olhe as letras
Esta é uma dica de quem entende do assunto que muitos artigos pulam.
Se você dá zoom e as letras parecem ligeiramente borradas, irregulares ou com aspecto de foto, a página pode ser baseada em imagem. O texto real costuma permanecer nítido ao ampliar, porque está sendo renderizado como caracteres, não esticado como uma figura.
Tente a busca
Pressione Ctrl + F e procure uma palavra que você consegue ver claramente na página.
- Se a busca encontra a palavra, provavelmente há uma camada de texto.
- Se a busca não encontra nada, mesmo com a palavra ali na sua frente, a página pode ser uma digitalização ou conteúdo apenas de imagem.
Dito isso, um arquivo ainda pode ter uma camada de texto e bloquear a cópia por meio de permissões. Então um PDF pesquisável não é automaticamente um PDF copiável.
O que os usuários costumam tentar primeiro — e por que costuma falhar
A maioria das pessoas faz a coisa óbvia primeiro. Elas abrem o arquivo no Edge, no Chrome ou no Adobe Reader e tentam selecionar o texto arrastando. Quando isso falha, elas supõem que o Windows está com defeito ou que o visualizador de PDF é ruim.
Então começa o caminho errado.
- Elas tentam outro aplicativo de PDF e têm o mesmo resultado.
- Elas enviam o documento para um conversor online qualquer.
- Elas convertem o PDF inteiro mesmo precisando só de um parágrafo.
- Elas tiram uma captura de tela e redigitam o texto à mão.
- Elas perdem tempo resolvendo o problema errado, porque o problema é o próprio arquivo, não o leitor.
Esse padrão acontece porque o sintoma é o mesmo em causas diferentes. Um PDF bloqueado e um PDF digitalizado podem ambos dar a sensação de “não consigo copiar este texto”, mas o motivo é completamente diferente.
Essa é uma distinção importante:
- PDF digitalizado: não há texto real para copiar.
- PDF bloqueado: pode haver texto real, mas o visualizador não está permitindo a cópia.
- Imagem dentro do PDF: só aquela parte da página precisa de OCR, não necessariamente o documento inteiro.
Opções integradas e grátis que vale a pena tentar primeiro
Antes de partir para o OCR, faz sentido tentar o caminho simples.
Edge, Chrome ou Adobe Reader
Se o PDF contém texto real e nenhuma restrição de cópia está bloqueando você, esses visualizadores integrados ou comuns costumam ser suficientes. Destaque o texto, copie e siga em frente.
Esse é o caminho de menor atrito, e o caminho certo quando funciona.
PDF pesquisável, mas a cópia mesmo assim falha
Se o documento é pesquisável mas a cópia falha, o arquivo pode estar restrito. Nesse caso, trocar de visualizador pode não ajudar, porque a restrição faz parte das regras do arquivo.
OCR por meio de um conversor completo
Se o PDF é digitalizado e você precisa do arquivo inteiro transformado em texto pesquisável, um fluxo completo de OCR pode fazer sentido. Isso é mais relevante quando você está lidando com um relatório longo, várias páginas ou documentos de arquivo.
O problema é que essa abordagem costuma ser desproporcional para o uso normal do dia a dia. Se tudo o que você precisa é um endereço, uma citação, um parágrafo ou um bloco de uma captura de tela embutida dentro do PDF, converter o arquivo inteiro é desajeitado.
Quando o OCR é realmente necessário
OCR significa Reconhecimento Óptico de Caracteres (em inglês, Optical Character Recognition). Ele lê as letras visíveis em uma imagem e as transforma em texto de verdade que você pode copiar.
O que é OCR? OCR é o processo de reconhecer texto a partir de uma imagem, digitalização, captura de tela ou outra fonte visual e convertê-lo em texto editável e selecionável.
Você precisa de OCR quando não há uma camada de texto utilizável da qual copiar diretamente.
Isso inclui casos comuns como:
- um contrato ou carta digitalizada
- uma foto transformada em PDF
- uma tabela ou diagrama salvo como imagem dentro do PDF
- uma digitalização de escritório de baixa qualidade
- um slide de apresentação exportado para um PDF como imagens
- texto visível em um quadro de vídeo, captura de tela ou janela de aplicativo
É aqui que muita gente perde tempo tentando “desbloquear” algo que não está bloqueado de jeito nenhum. Simplesmente não há texto ali para copiar, para começo de conversa.
O meio-termo inteligente: OCR visual em vez de conversão completa
Se o seu objetivo é capturar apenas o texto que você já consegue ver na tela, o OCR do documento inteiro costuma ser exagero.
É aí que o Screenie OCR Text Recognition Tool se encaixa bem. Em vez de reconstruir o PDF inteiro, ele extrai o texto da região visível que você seleciona na tela.
Isso o torna especialmente prático quando:
- você só precisa de algumas linhas, não do arquivo inteiro
- o PDF contém uma página digitalizada ou uma captura de tela embutida
- você está copiando texto de um gráfico, imagem ou diagrama
- o texto está visível em um site, aplicativo, apresentação ou legenda de vídeo
- você não quer passar por um fluxo completo de conversão de PDF só para pegar um pequeno trecho
Diante dessas contrapartidas, a decisão fica direta:
- Use a cópia integrada quando o PDF contém texto real e selecionável.
- Use OCR completo ou conversão quando você precisa processar o documento inteiro.
- Use OCR visual quando o trabalho real é simplesmente capturar texto visível rapidamente.
É por isso que o Screenie funciona como uma recomendação prática aqui. Ele é mais simples do que um editor de OCR completo, mais rápido do que converter um arquivo inteiro por causa de um parágrafo, e mais adequado para situações de “preciso deste texto agora”.
Como extrair texto de um PDF no Windows em menos de um minuto
Estes passos funcionam especialmente bem quando o texto está visível, mas não selecionável.
-
Abra o PDF no seu visualizador de sempre. Edge, Chrome e Adobe Reader servem perfeitamente. Você não precisa mover o arquivo para lugar nenhum.
-
Encontre a região exata de que você precisa. Role até o parágrafo, a legenda, a tabela ou a área da imagem que contém o texto que você quer.
-
Verifique primeiro se a cópia integrada funciona. Tente selecionar uma palavra. Se o destaque normal funcionar, é só copiar diretamente e pular o OCR.
-
Use o Screenie quando a seleção falhar. Abra o Screenie OCR Text Recognition Tool e ative a área de captura.
-
Desenhe uma caixa em volta do texto visível. Selecione só a parte de que você realmente precisa. Isso costuma melhorar a velocidade e deixar o resultado mais limpo.
-
Cole o texto extraído onde você precisar. Depois que a captura termina, cole no Word, no e-mail, em anotações, no Slack ou onde quer que você esteja trabalhando.
Essa abordagem visual costuma ser mais rápida do que exportar, converter ou rodar OCR em um arquivo inteiro quando a tarefa real é pequena.
Casos específicos importantes que confundem as pessoas
Um contrato digitalizado que parece normal
Um contrato digitalizado pode parecer um PDF digital comum, porque as letras aparecem nítidas o suficiente na tela. Mas se arrastar o cursor seleciona a página como uma única imagem, o OCR é necessário.
Um PDF que é parcialmente selecionável
Esse é um forte indício de que o arquivo contém conteúdo misto. O texto do corpo pode ser real, enquanto assinaturas, capturas de tela, barras laterais ou diagramas são baseados em imagem. Nesse caso, use a cópia normal onde ela funciona e o OCR só onde não funciona.
Texto dentro de gráficos, tabelas e capturas de tela
Mesmo em um PDF normal, o texto dentro de elementos gráficos embutidos muitas vezes não é selecionável. A cópia padrão do PDF pode funcionar para os parágrafos, mas falhar nos rótulos dentro do gráfico. Uma ferramenta de OCR visual costuma ser a melhor opção para essa região.
Digitalizações de baixa resolução
O OCR não faz milagre. Se a origem está borrada, torta, muito comprimida ou com pouco contraste, a precisão do reconhecimento pode cair. Isso não depende só da ferramenta; depende também da qualidade da origem.
Layouts de várias colunas
Alguns fluxos de OCR podem ficar confusos quando a página tem colunas estreitas, notas laterais ou elementos visuais sobrepostos. Selecionar uma região menor em vez da página inteira costuma dar um resultado mais limpo.
Esse último ponto importa mais do que a maioria das pessoas imagina. Converter o PDF inteiro nem sempre é a escolha mais inteligente. Quando o layout é complicado, pegar só a parte visível que interessa pode produzir resultados práticos melhores.
Solução de problemas: se a extração ainda estiver bagunçada
Se você está obtendo um texto ruim ou incompleto, o arquivo pode não ser o único problema. Tente estas verificações.
As letras parecem borradas
Dê zoom. Se a digitalização está embaçada, a precisão do OCR normalmente vai sofrer. Um nível de zoom mais limpo ou uma área de captura mais justa podem ajudar.
A página tem conteúdo misto
Não capture a página inteira se só uma caixa ou um parágrafo importa. Pegar uma região menor costuma reduzir a confusão.
O layout tem colunas ou notas laterais
Pegue uma coluna ou uma seção de cada vez, em vez de tentar fazer o OCR da página inteira de uma só vez.
O PDF parece bloqueado
Se você consegue pesquisar o texto mas não copiá-lo, o arquivo pode estar restrito, e não digitalizado. Nesse caso, uma abordagem de OCR visual ainda pode ser a solução mais rápida para pequenos trabalhos de extração.
Você só precisa de uma citação curta
Não perca tempo convertendo o documento inteiro. Esse é exatamente o tipo de situação em que o OCR visual direcionado faz mais sentido do que um fluxo completo de PDF.
Quando uma ferramenta de OCR completa faz mais sentido
Para manter a honestidade: o Screenie não é a resposta para todo problema de PDF.
Um editor de OCR completo ou um fluxo de OCR de documentos pode ser a melhor opção quando:
- você precisa converter o PDF inteiro em um documento pesquisável
- você está processando muitas páginas de uma vez
- você precisa de recursos de edição, anotação ou reconstrução de arquivo
- você quer preservar a estrutura do documento ao longo do arquivo inteiro
Mas isso não é o mesmo trabalho que tirar rapidamente o texto de uma única região visível.
Este artigo é, na verdade, sobre uma frustração comum e prática: o texto está na sua tela, mas a cópia normal não funciona. Para esse problema exato, um fluxo de OCR visual costuma ser a solução mais limpa.
Você também pode explorar outros guias práticos para Windows no blog da RoxyApps se lida com problemas parecidos de PDF, capturas de tela ou extração de texto.
Perguntas frequentes (FAQ)
Por que não consigo copiar o texto de um PDF se consigo lê-lo com clareza?
Porque um texto legível na tela nem sempre é texto real e selecionável. A página pode ser uma digitalização, uma imagem embutida ou conteúdo com restrições de cópia.
Como sei se um PDF é digitalizado ou baseado em texto?
Tente destacar uma palavra e use a busca com Ctrl + F. Se a página inteira se comporta como uma única imagem ou a busca não encontra palavras visíveis, o PDF provavelmente é digitalizado ou baseado em imagem.
Um PDF bloqueado e um PDF digitalizado podem parecer iguais?
Sim. Os dois podem produzir o mesmo sintoma: você não consegue copiar o texto. A diferença é que um PDF digitalizado não tem camada de texto, enquanto um PDF bloqueado pode conter texto real, mas impedir a cópia por meio de permissões.
Qual é a forma mais rápida de extrair texto de um PDF digitalizado no Windows?
Se você precisa do documento inteiro convertido, um fluxo completo de OCR pode ser apropriado. Se você só precisa de uma parte visível rapidamente, uma ferramenta de OCR visual como o Screenie costuma ser mais rápida e mais simples.
O OCR funciona só para PDFs?
Não. O OCR também consegue extrair texto de capturas de tela, imagens digitalizadas, gráficos, aplicativos, sites, apresentações e até legendas de vídeo, desde que o texto esteja visível na tela.
Por que só parte do meu PDF deixa copiar texto?
Isso normalmente significa que o arquivo contém conteúdo misto. Algumas seções podem ser texto real, enquanto outras são capturas de tela, digitalizações ou elementos gráficos embutidos que exigem OCR.
”PDF com OCR” é um tipo especial de PDF?
Não exatamente. As pessoas costumam se referir a um PDF que passou pelo OCR para que o texto baseado em imagem fique pesquisável ou extraível. É a descrição de um fluxo de trabalho, não uma espécie separada de PDF.
É necessário converter o PDF inteiro se eu só preciso de um parágrafo?
Normalmente não. A conversão do documento inteiro costuma ser desnecessária quando o seu objetivo real é capturar um parágrafo visível, uma célula de tabela, uma legenda ou uma região de captura de tela.
Dá para extrair texto de um PDF bloqueado sem reconstruir o arquivo inteiro?
Para uma pequena seção visível, sim. Um fluxo de OCR visual muitas vezes consegue pegar o texto de que você precisa sem te obrigar a um processo completo de conversão do documento.